コネクタープライベートネットワーキングの紹介 : 今後のウェビナーに参加しましょう!
Announcing Confluent 3.1 with Apache Kafka 0.10.1.0
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Today, we are excited to announce the release of Confluent 3.1, the only stream processing platform built entirely on Apache Kafka. At Confluent, our vision is to not only ship the most up to date version of Kafka but also make it ready for the enterprise. We first delivered on that promise when we announced version 3.0.0, including Confluent Control Center, the first comprehensive management and monitoring system for Kafka, and initial feedback has been overwhelmingly positive.
For 3.1, we have further extended Control Center plus added even more features and bug fixes to further deliver on our Kafka for the enterprise vision. The lack of efficient and operable data rebalancing and multi-datacenter replication functionalities in Kafka have been a pain point for many customers, and we have addressed these in our most recent Confluent Platform release with the addition of Automatic Data Balancing and Multi-datacenter replication.
In addition, we have built more connectors (Elasticsearch and JDBC Sink), introduced a new high performing Go Client, and have addressed critical bug fixes to other Confluent open source components. Lastly, this version also includes the latest Kafka release 0.10.1.0. In total, this release includes the completion of 15 Kafka Improvement Proposals (KIPs), over 200 bug fixes and improvements, and over 500 merged pull requests. A full list of the new features, improvements, and bug fixes can be found in the release notes.
New in Confluent Platform
Automatic Data Balancing
As clusters grow, topics and partitions grow at different rates, brokers are added and removed, and over time this leads to unbalanced workloads across data center resources: some brokers are under-utilized, while others are heavily taxed with large or many partitions, slowing down message delivery. Auto Data Balancing helps alleviate this problem by monitoring your cluster for number of brokers, size of partitions, number of partitions and number of leaders within the cluster and shifts data to create an even workload across your cluster.
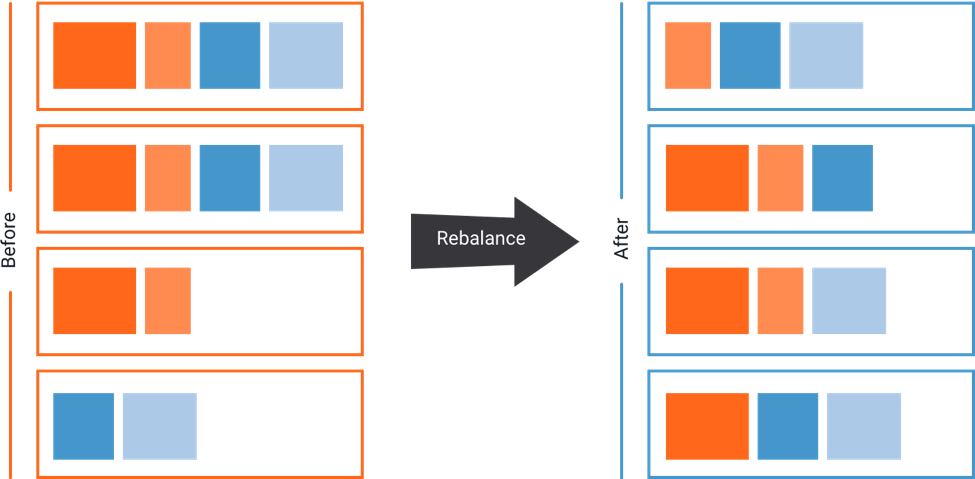
A correctly balanced cluster means more efficient workload execution. Read more about this exciting new capability in the Auto Data Balancing section of the Confluent documentation.
Multi-datacenter Replication
Confluent Platform now makes it easier than ever to maintain multiple Kafka clusters in multiple data centers. Managing replication of data and topic configuration between data centers enables use-cases such as:
- Active-active geo-localized deployments: allows users to access a nearby data center to optimize their architecture for low latency and high performance
- Centralized analytics: Aggregate data from multiple Kafka clusters into one location for organization-wide analytics
- Cloud migration: Use Kafka to synchronize data between on-prem applications and cloud deployments
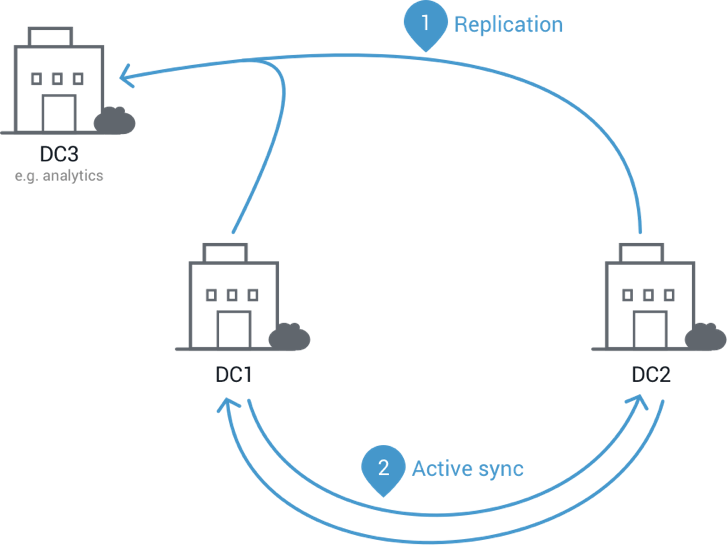
The new Multi-Datacenter Replication feature allows configuring and managing replication for all these scenarios from either Confluent Control Center or command-line tools. More information about this feature can be found in the Confluent 3.1 documentation.
Confluent Control Center
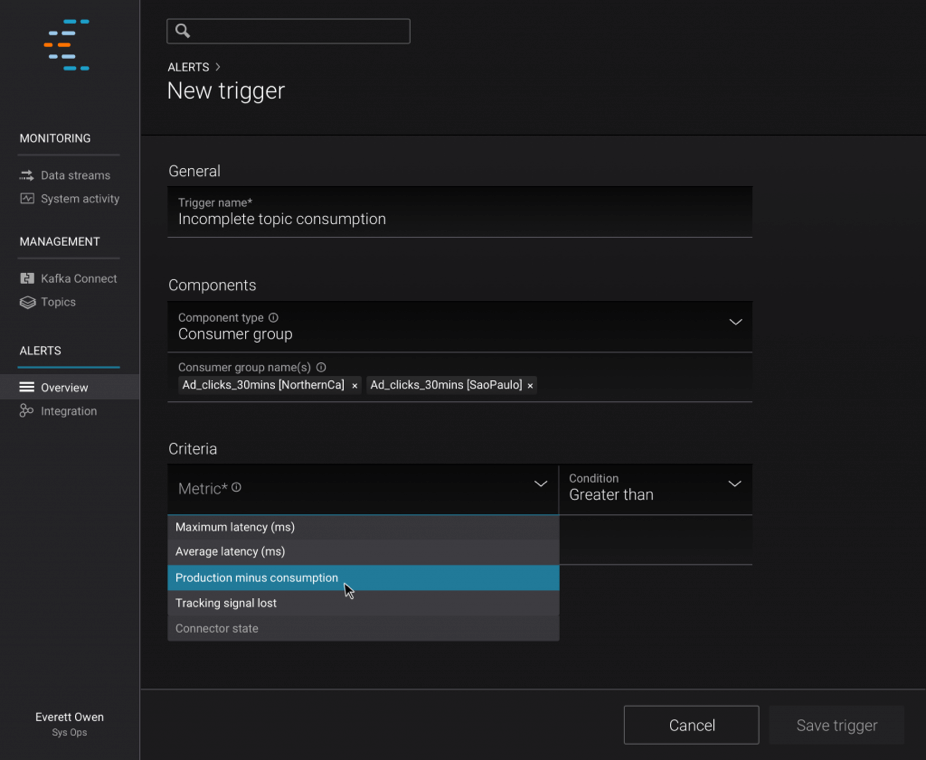
Control Center now has the capability to define alerts on the latency and completeness statistics of data streams, which can be delivered by email or queried from a centralized alerting system. This version also makes it really easy to integrate with enterprise authentication systems which helps to protect the access to Control Center. In this release, the stream monitoring features have also been extended to monitor topics from across multiple Kafka clusters.
New in Confluent Open Source
Connectors and Clients
In this release, we’ve added two new connectors and one new client:
ELASTICSEARCH SINK
We built a high-performance connector to stream data from Kafka to Elasticsearch. This connector supports automatic generation of Elasticsearch mappings, all Elasticsearch datatypes and exactly-once delivery. We have received excellent feedback about the connector from our early adopters and we are continuing to make it better.
JDBC SINK
The JDBC sink connector allows you to export data from Kafka topics to any relational database with a JDBC driver. By using JDBC, this connector can support a wide variety of databases without requiring a dedicated connector for each one. The connector polls data from Kafka to write to the database based on the topics subscription. It is possible to achieve idempotent writes with upserts. Auto-creation of tables, and limited auto-evolution is also supported.
GO CLIENT
We’re introducing a fully supported, up to date client for Go. The client is reliable, high-performance, secure, compatible with all versions of Kafka and supports the full Kafka protocol. You can read more here about the client and take it for a spin.
Getting Started
One of the easiest ways to get started is to try a trial of Confluent Platform. Details can be found on our download page or you can learn more by reading our documentation.
Confluent Platform 3.1 is backed by our subscription support. We also offer expert training and technical consulting to help get your organization started. As always, we are happy to hear your feedback. Please post your questions and suggestions to the public Confluent Platform mailing list.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...