Fast, Frictionless, and Secure: Explore our 120+ Connectors Portfolio | Join Webinar!
Elastically Scaling Confluent Platform on Kubernetes
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
This month, we kicked off Project Metamorphosis by introducing several Confluent features that make Apache Kafka® clusters more elastic—the first of eight foundational traits characterizing cloud-native data systems that map to key product announcements for the coming year.
Cloud-native data systems are expected to scale up as demand peaks and scale down as demand falls, removing the need for detailed capacity planning while ensuring businesses and applications built on top of Kafka can meet the real-time expectations of customers.
The same expectations of elasticity for fully managed data systems hold for self-managed environments, whether deploying on prem or in the cloud. That’s why, just as we are doing with Confluent Cloud, we are continuing to introduce product features in Confluent Platform that enable Kafka users to scale their self-managed clusters with the benefits of elasticity. These features include fully automated partition rebalancing, decoupling of Kafka’s storage and compute layers, and orchestration of Kafka on a cloud-native runtime like Kubernetes. We’ll walk through some of the scaling challenges these capabilities address, and we will also highlight a sneak peek demo of the features so you can see them in action.
The non-elastic way: Scaling self-managed Kafka with several manual steps
Whenever a Kafka cluster is initially deployed, capacity planning is crucial to determining the number of brokers needed to meet the demands of its first use case. Over-provisioning compute and storage resources to the cluster can be quite costly to the business. Because the resource needs of the cluster will change as more and more data is sent into Kafka, an ideal solution is to start with a smaller, efficient cluster and then expand it as the use case expands.
At a high level, adding brokers to a cluster requires a few key steps:
- Define the configuration for each of the new brokers
- Provision storage, networking, and compute resources to the brokers
- Start the brokers with the defined configurations and provisioned resources
- Reassign partitions across the cluster so that the new brokers share the load and the cluster’s overall performance improves
This process is not without its challenges. Each step is quite manual, meaning that it both consumes time that could be otherwise spent on high-value projects and is more prone to human error. For the last step in particular, rebalancing partitions across the brokers is not only complex but can also result in diminished cluster performance as partitions are shifted.
The elastic way: Scaling with Confluent Platform
Confluent Platform will soon have three key features that significantly simplify the process of scaling a Kafka cluster:
- Kubernetes Operator (currently available): simplifies running Kafka as a cloud-native data system, whether on premises or in the cloud, by allowing you to programmatically provision Kafka resources with proper compute, storage, networking, and security options. Operator deploys a standardized architecture that is based on the expertise and best practices accumulated by Confluent from running Kafka at scale on Kubernetes in Confluent Cloud. This means we bring a consistent operational experience for cloud-native data systems across on prem and cloud.
- Tiered Storage (currently in preview): allows Kafka to recognize two tiers of storage: local disks and cost-efficient object stores, like Amazon S3. This enables you to scale compute without having to scale storage, and vice versa. Furthermore, after scaling compute, rebalancing of data becomes easier and faster, because new nodes can point to data in the object storage layer, minimizing the amount of data that needs to move from one node to another. It’s similar for scaling storage when retention or throughput requirements go up.
- Self-Balancing Clusters (coming soon): the last piece of the puzzle, which we will introduce later this year. Self-Balancing Clusters will automatically recognize the presence of new brokers in the cluster and trigger rebalancing operations accordingly, to optimize Kafka’s throughput, accelerate broker scaling, and reduce the operational burden of running a large cluster.
Each of these features on their own are tremendously valuable, whether you want to deploy on Kubernetes, increase the amount of data stored in Kafka, or eliminate any need to manually rebalance a cluster. But isolating the value of each feature doesn’t tell the whole story, as they complement one another in ways that transform Kafka into a data system that is more elastic.
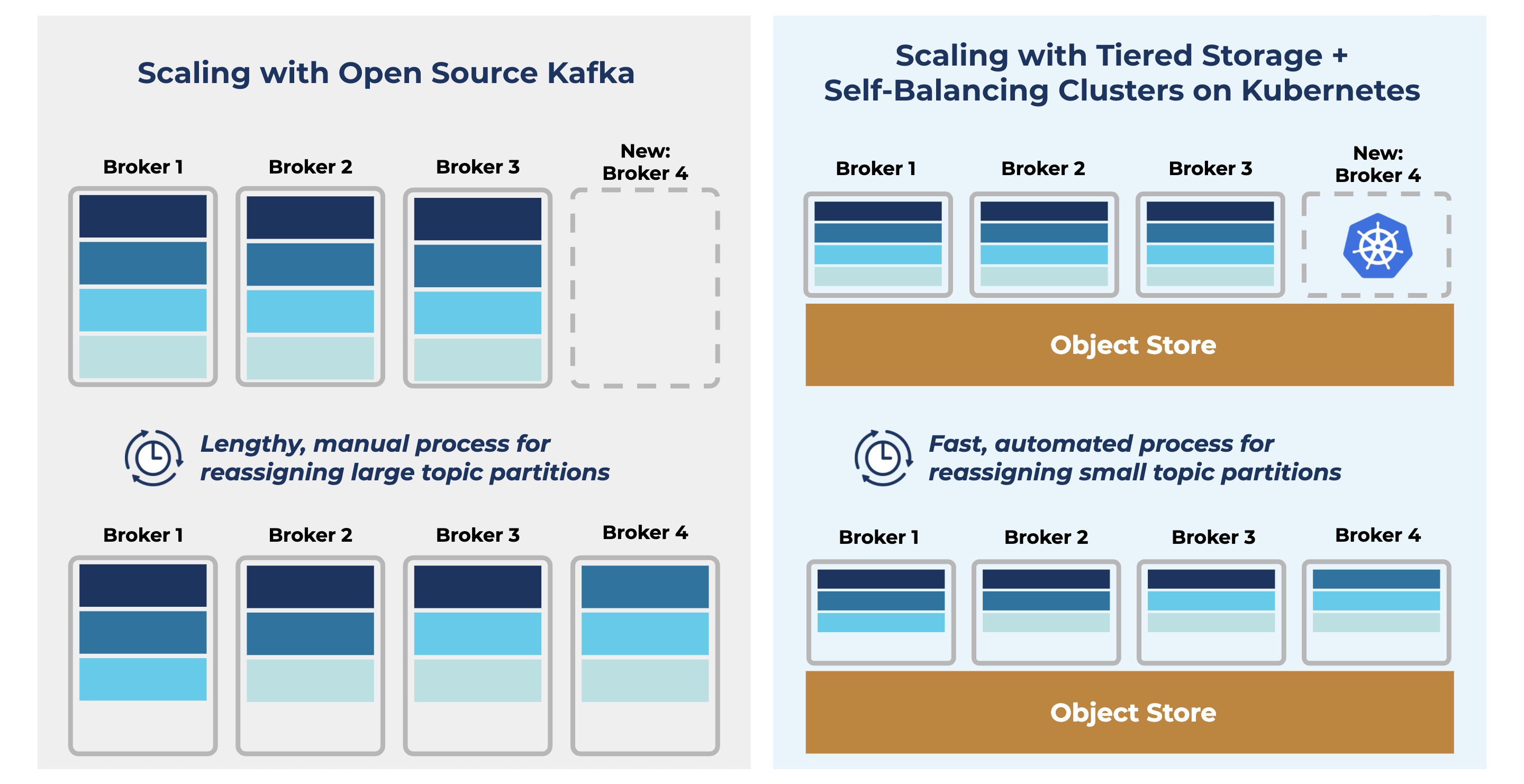
Let’s consider the four steps of adding brokers that we previously outlined. Operator enables you to programmatically configure, provision, and deploy additional brokers to a cluster running on Kubernetes, thus accomplishing steps 1 through 3 in a far more automated and reliable manner. Additionally, Operator will soon be fully compatible with Self-Balancing Clusters, which abstracts away the final step of the process for rebalancing partitions. Expanding a Kafka cluster will then be as simple as running a single command.
Because Kafka tightly couples storage and compute resources, brokers are often added to a cluster as a means of providing it with additional storage. With Operator, you can simply scale up disk capacity for the existing brokers without needing to add new brokers to the cluster. Broker storage can be expensive though, and each partition needs to be replicated several times for durability. Tiered Storage, which will also soon be fully compatible with Operator, solves this problem. With Tiered Storage, you can leverage cheaper object storage and can scale up storage and compute resources independently of one another, enabling even more efficient scaling of the cluster’s infrastructure.
Tiered Storage also fundamentally changes the length of time needed to complete a rebalance when brokers are added. Because partition replicas hold less data on the broker itself, partition reassignments also require less data to be shifted across the cluster. Combining Tiered Storage and Self-Balancing Clusters means that adding brokers results in more immediate performance benefits without the typical time delay and operational burden of completing a rebalance.
In summary, the synergy of Operator to orchestrate cluster expansion and resource provisioning via Kubernetes, Tiered Storage to enable “lightweight” Kafka brokers that decouple compute from storage, and Self-Balancing Clusters to automatically optimize resource utilization will make dynamic scaling fast and easy.
Demo: Elastically Scaling Kafka on Kubernetes with Confluent Platform
Now that we have explained what it means to elastically scale with Confluent Platform, check out the following demo with Tim Berglund to see each of the features in action as they scale a cluster from three brokers to 12 brokers, while simultaneously scaling up disk from 24 GB to 240 GB per broker, all with a single command.
To learn about other work that is happening to make Kafka elastically scalable, check out the following resources:
- Project Metamorphosis Month 1: Elastic Apache Kafka Clusters in Confluent Cloud
- Apache Kafka Needs No Keeper: Removing the Apache ZooKeeper Dependency
- Scaling Apache Kafka to 10+ GB Per Second in Confluent Cloud
Big thanks to Amit Gupta, who was the architect of the demo above showing the future state of Confluent Platform.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...