Introducing Connector Private Networking: Join The Upcoming Webinar!
Introducing a Cloud-Native Experience for Apache Kafka in Confluent Cloud
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
In the last year, we’ve experienced enormous growth on Confluent Cloud, our fully managed Apache Kafka® service. Confluent Cloud now handles several GB/s of traffic—a 200-fold increase in just six months. As Confluent Cloud has grown, we’ve noticed two gaps that very clearly remain to be filled in managed Apache Kafka services. First, all the Kafka services out there still require you to size and provision a cluster, which inevitably leads to a poor developer experience, over-provisioned capacity and inefficient cost structure. Second, none of them yet provide the complete event streaming experience that developers need to build event-driven applications—that is, developers do not live by Kafka alone.
And, turning complex distributed data systems—like Apache Kafka—into elastically scalable, fully managed services takes a lot of work, because most open source infrastructure software simply isn’t built to be cloud native. Other vendors claim to provide managed services around commodity open source data infrastructure, but that often consists of little more than a set of scripts for deploying the software to managed servers and exposing an IP address. They have none of the elasticity, flexible pricing, strong SLAs, or rich platform ecosystem that you need if you are trying to build scalable systems in the cloud.
Today, I am pleased to announce a big step forward for Confluent Cloud, making it the industry’s first cloud-native event streaming service: You can now elastically scale production workloads from 0 to 100 MB/s and down instantaneously without ever having to size or provision a cluster, scale production workloads from hundreds of MB/s to tens of GB/s with provisioned capacity, and pay only for the data you actually stream to Kafka rather than pay for over-provisioned cluster capacity.
Not only that, as we had previously promised, we are also introducing three of the most popular components of Confluent Platform as fully managed services: Confluent Schema Registry, the Kafka S3 sink connector, and Confluent KSQL.
Five seconds to Kafka (or, never make another cluster again!)
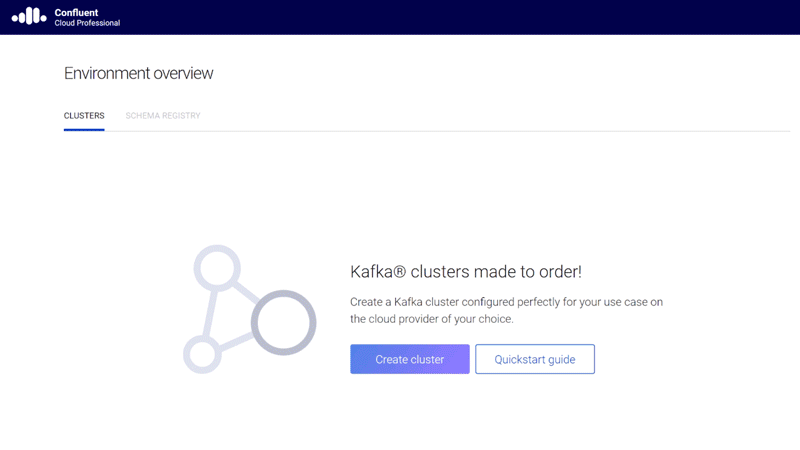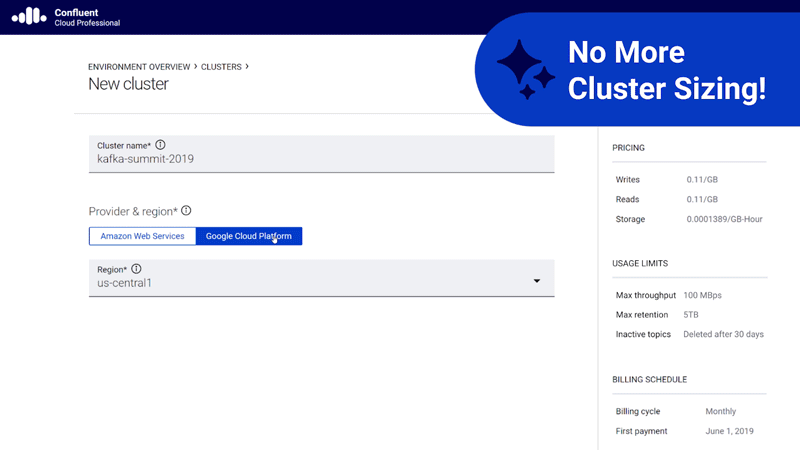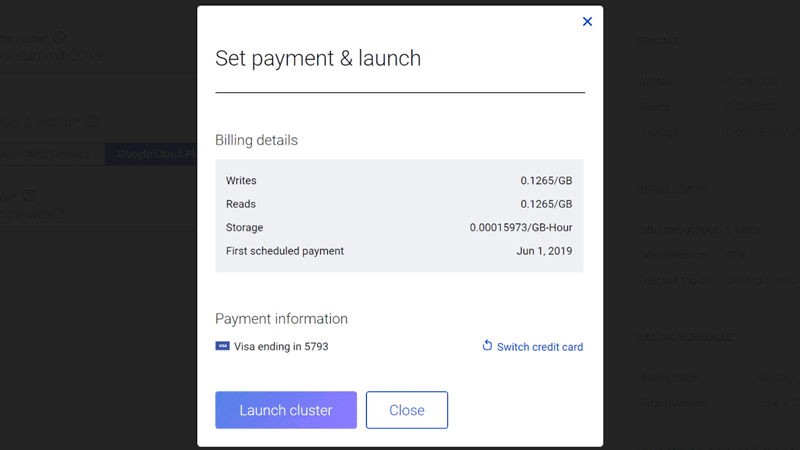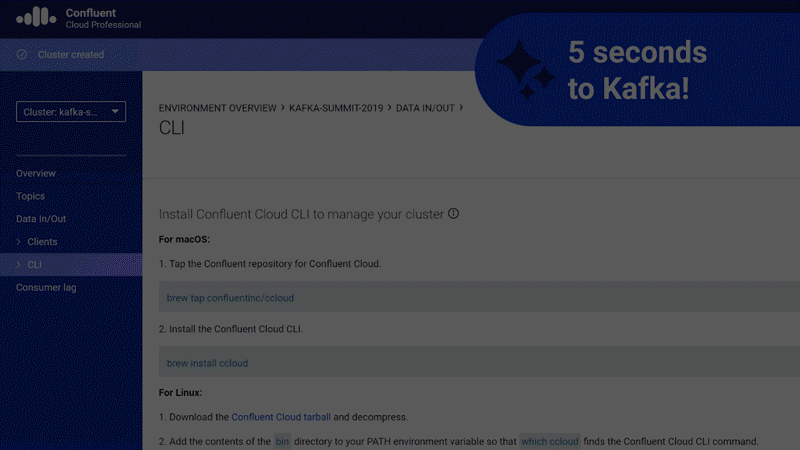
If you are using Kafka as a fully managed service, you might step back and ask whether the notion of a cluster still means anything. When you are deploying your own infrastructure, it’s quite necessary to think of discrete clusters, but when you’re using a cloud-native Kafka service, the concept begins to seem like unnecessary baggage held over from the on-prem world. In the cloud, clusters become a mere detail of the plumbing, an abstraction that we should not have to think about. It’s time for Confluent Cloud to leave them behind, giving you a five-seconds-to-Kafka experience, without ever having to size or provision a cluster.
Elastically scale from 0 to 100 MBps and beyond
The fundamental problem with provisioning clusters in the cloud is that you always have to over-provision capacity. Traffic to the service is usually not uniform over time—it has peaks and troughs—so you have to size your cloud clusters such that they can sustainably handle your peak load while still meeting your latency SLAs. You can make this work and still gain the benefit of having the cluster managed for you by the cloud provider. However, it can never fully realize the economics of the cloud. If you provision clusters, you will always carry the burden of sizing and pay more than you need to.
To build this service, we had to tackle a number of challenges. First, we found that elasticity is not trivial: When usage spikes, there is no time to boot new containers or add nodes to a cluster. And Kafka was not the only thing we had to scale! We also had to work around various limits on cloud infrastructure, like limits on the number of VPCs and elastic load balancers per account. Elasticity also meant that we needed to do continuous, intelligent data balancing across the various nodes of a Kafka cluster. And finally, doing that efficiently required that we work to minimize the data we had to move around on each rebalance event.
We’re excited that Confluent Cloud now enables instant access to capacity, allowing you to elastically scale your Kafka workloads from 0 to 100 MB/s and back down in seconds, without having to worry about sizing or provisioning anything. You can grow seamlessly from your initial exploratory code to a full velocity development effort, all the way to production. You don’t need to predict what your volume will be, and you don’t need to over-provision to make sure you can accommodate the occasional burst in producer or consumer bandwidth.
If your needs expand beyond 100 MB/s, Confluent Cloud will continue to scale with you and support tens of GB/s using a provisioned capacity model, all while ensuring uptime SLAs and availability.
No minimums: Pay only for what you actually stream
With fixed cluster provisioning comes the associated concern of overpaying for capacity. You’re paying for peak provisioned capacity instead of consumed capacity—and the ratio between the two can be as high as 10x at times. And even if your load is fairly constant, you will still tend to provision for future growth, which still leaves you with unused capacity that you are paying for.
Instead of charging you for peak capacity, Confluent Cloud now charges you only for the data that you actually stream, and never for the streaming you don’t do. Our fully transparent consumption-based pricing can give you a realistic production cluster for $50 per month and requires no commitment—you can leave the service at any time with no fees.
Actual unit prices are based on three simple consumption metrics. We measure GB of data written to or read from Confluent Cloud, with prices starting at $0.11 per GB. And we measure GB of data retained on Confluent Cloud, with prices starting at $0.10 per GB per month. That’s all you pay, which means that your prices will scale completely linearly with your consumption.
Fully managed Schema Registry, Kafka S3 sink connector, and ksqlDB in Confluent Cloud
Apache Kafka provides an outstanding foundation for building contextual event-driven applications, but as the Kafka community has repeatedly discovered, Kafka at the core exposes the need for APIs that must be present in order to build real applications. Components like Confluent Schema Registry, our extensive library of Kafka Connect connectors, and stream processing tools like ksqlDB have all emerged to fill these gaps.
Confluent Schema Registry, the Kafka S3 sink connector, and ksqlDB are all available as fully managed services in Confluent Cloud in public preview today. Public preview means that the features are available for you to evaluate, and we are open to your feedback on them. While we do not recommend them for production use just yet, we are looking forward to these features being generally available soon.

Kafka Connect is a declarative data integration framework that lets you integrate Kafka with legacy systems without writing custom producers and consumers. Today, we are making the popular Kafka S3 sink connector available as a fully managed service. This is a first step forward in offering a large ecosystem of fully managed connectors for Apache Kafka.
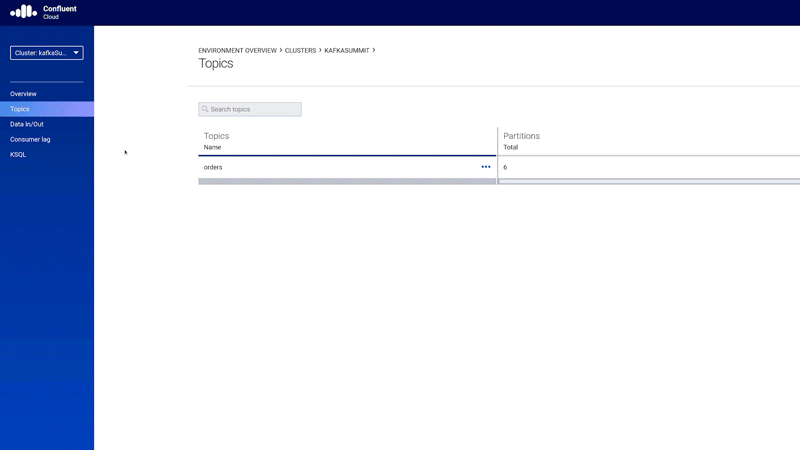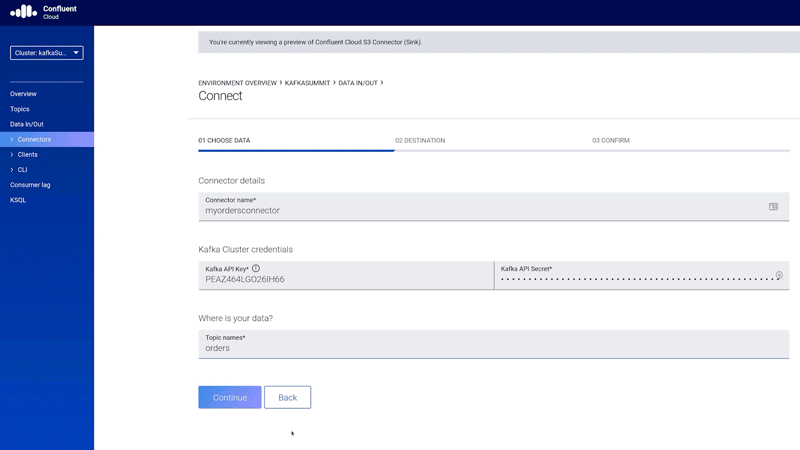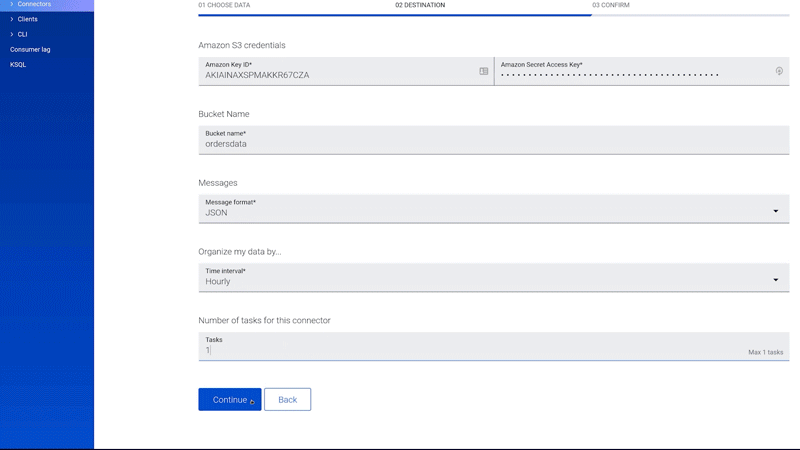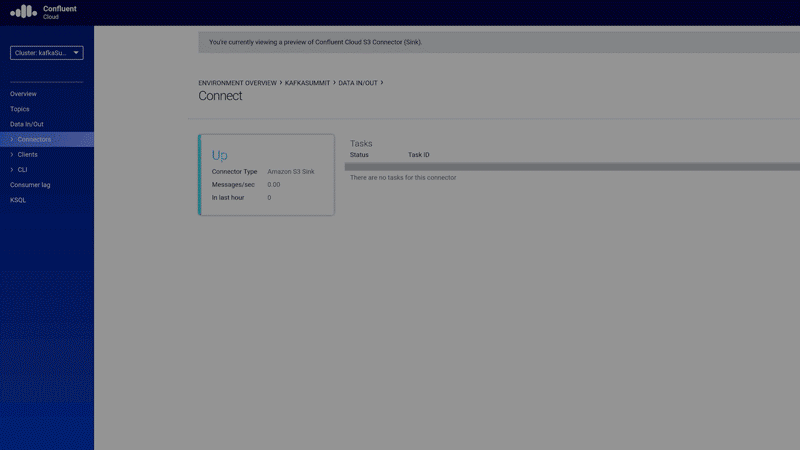
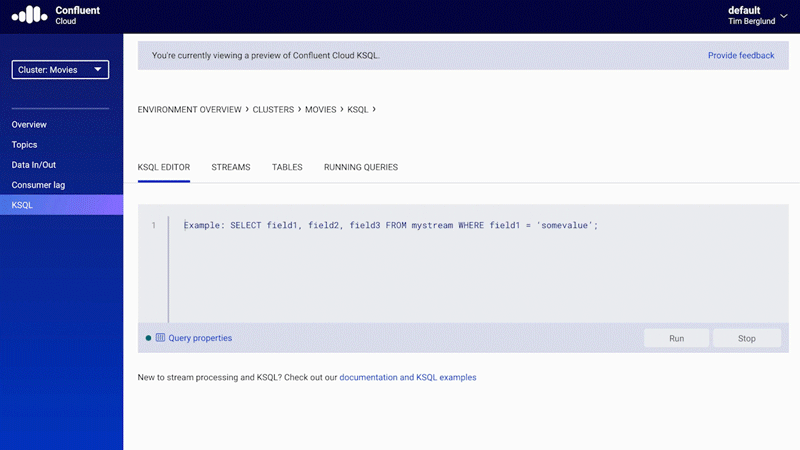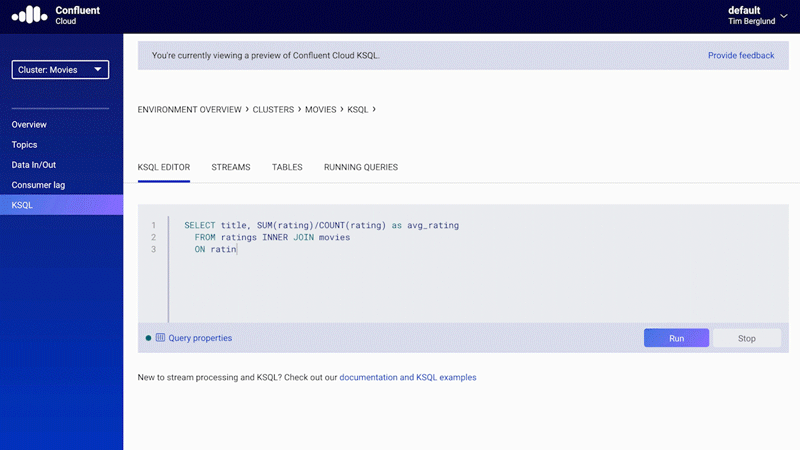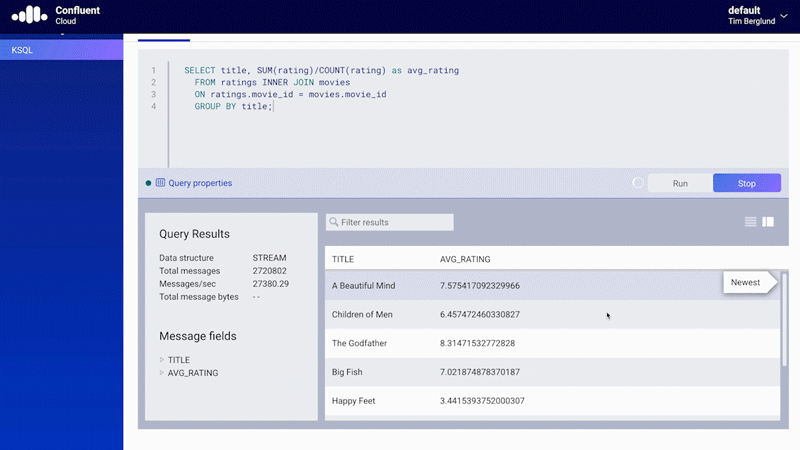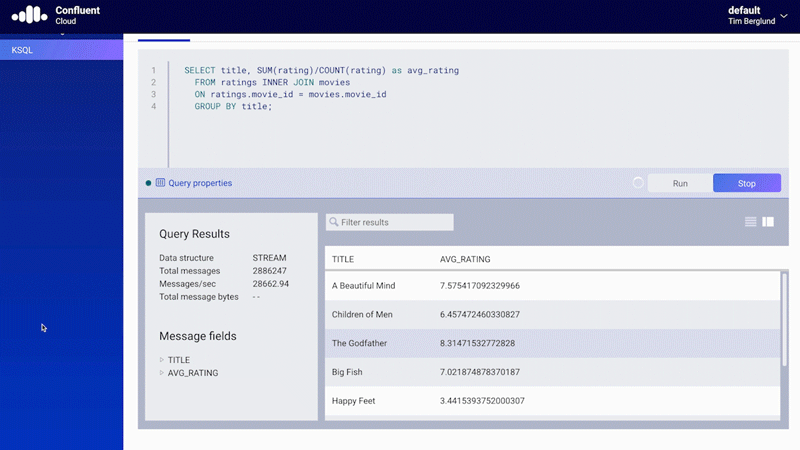
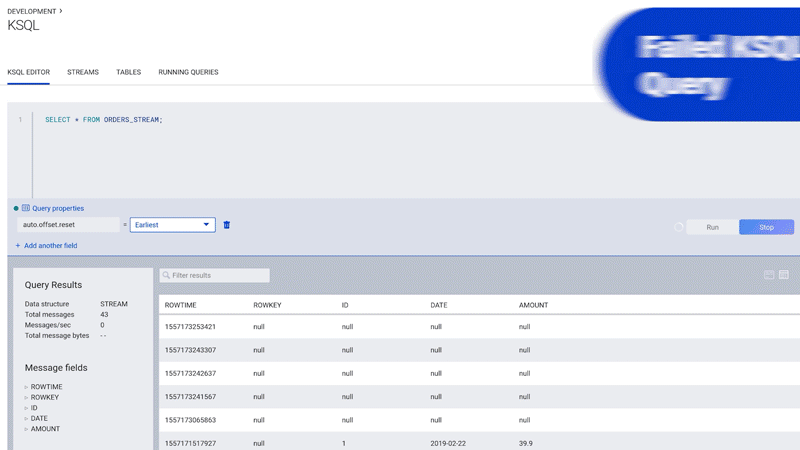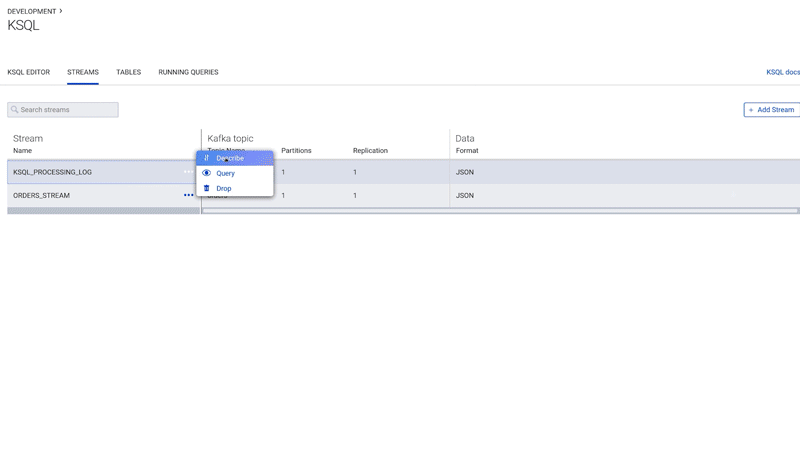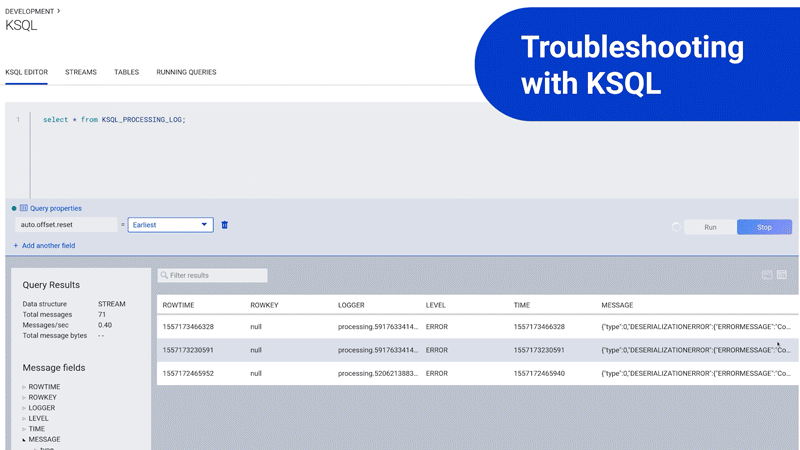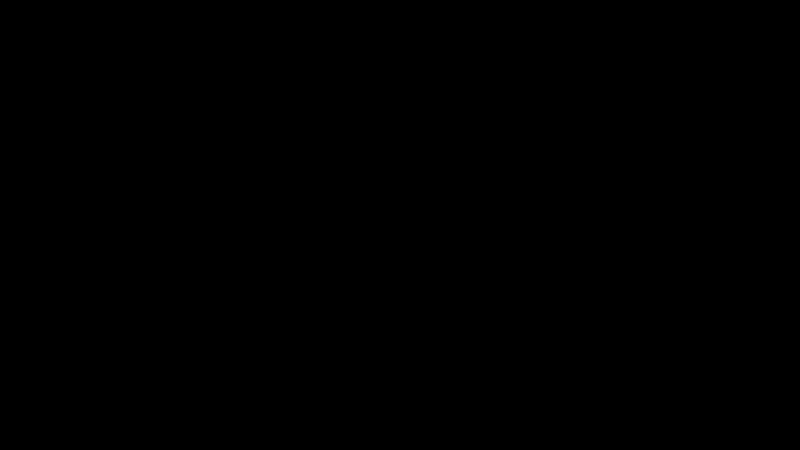
ksqlDB is a declarative, SQL-like stream processing language you can use to write stream processing programs that perform continuous, real-time computations over event streams in Kafka. Fully managed ksqlDB in Confluent Cloud allows you to quickly look inside Kafka topics, do stream processing, as well as troubleshoot ksqlDB queries using a structured processing log that can also be conveniently queried using ksqlDB!
A cloud-native, complete event streaming platform
Today’s announcement is a key part of our vision to provide the cloud-native, complete event streaming platform you need to build the contextual event-driven applications that power today’s event-driven enterprise. You need cloud-native scalability that scales from zero to enterprise production capacities as quickly as possible, without forcing you to think about infrastructure or capacity planning at all.
And remember, you can’t get by on just Kafka topics! You need hosted schema management, hosted Kafka connectors, and fully managed stream processing at the touch of a button—which are all ready for you to evaluate now.
Learn more about Apache Kafka as a service
To learn more, check out Confluent Cloud, a fully managed event streaming service based on Apache Kafka. Use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage.*
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...