コネクタープライベートネットワーキングの紹介 : 今後のウェビナーに参加しましょう!
Introducing Confluent Platform 5.3
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Delivers the new Confluent Operator for cloud-native automation on Kubernetes, a redesigned Confluent Control Center user interface to simplify how you manage event streams, and a preview of Role-Based Access Control for enterprise-grade security
Over the past year, we’ve been amazed at how fast Confluent Platform has matured within our user base—both in terms of size and criticality of deployments. If you’re like most users, chances are that Confluent Platform is rapidly becoming the new standard for integrating your data and applications to uncover new insights about your business, build real-time customer experiences, and create new business models.
However, deploying and operating a distributed data system at scale can be challenging. As you scale the platform to support additional use cases, you may be facing challenges around lengthy deployment cycles, operational complexity, or difficulties in ensuring enterprise-grade security.
To solve these challenges, Confluent Platform 5.3 delivers enhancements that will help you:
- Automate Apache Kafka® operations for production environments
- The new Confluent Operator simplifies running Confluent Platform as a cloud-native system on Kubernetes, on-premises, or in the cloud, by automating deployment tasks and key lifecycle operations. Confluent Operator is based on proven technology, already leveraged to run Confluent Cloud, our fully managed event streaming service, at scale and with mission-critical service levels.
- Open source, production-ready Ansible playbooks provide a simpler, more automated way of deploying Confluent Platform in non-containerized environments, fully supported by Confluent.
- Simplify management across user interfaces
- A redesigned user interface for Confluent Control Center provides a more intuitive user experience, making it easier to understand your deployments and manage them at scale.
- A new production-ready command line interface (CLI) provides a more idiomatic way of configuring Confluent Platform in production, with an upgraded experience on local installs and support for managing Role-Based Access Control.
- Secure the platform end to end
- A preview of Confluent Role-Based Access Control (RBAC) allows you to test out providing secure authorization to resources without having to assign individual privileges to each and every user. RBAC is enforced across Confluent Platform components and user interfaces.
- New Secret Protection encrypts secrets within the configuration file itself and does not expose the secrets in log files. It enables end-to-end secret protection across all Confluent Platform components.
Automate Kafka operations for production environments
Our goal is to simplify Kafka operations through automation so you can build more applications faster while ensuring a high level of consistency across environments.
Introducing Confluent Operator for Kubernetes
Kubernetes has become the open source standard for orchestrating containerized applications, but running stateful applications such as Kafka can be difficult and requires a specialized skill set. Thus, we decided to automate the process for you.
For the past few months, we have been working closely with a set of customers and partners as part of a preview program to gather their early feedback. We are now ready to release Confluent Operator, our enterprise-ready implementation of the Kubernetes Operator API to automate deployment and key lifecycle operations of Confluent Platform on Kubernetes.
Deploy to production in minutes
The first thing you’ll get with Operator is the ability to programmatically deploy and edit Kafka resources. Using Helm as the package manager, you can specify configurations for security and authentication, storage volumes, and the networking needed between platform components and to clients outside the Kubernetes cluster.
If you are using more components of Confluent Platform than just Kafka, remember that Confluent Operator can deploy Kafka Connect, KSQL, Schema Registry, Auto Data Balancer, Control Center, and Replicator in addition to Kafka and ZooKeeper. This level of automation helps you build a consistent, repeatable, and production-ready platform in a matter of minutes, so you can spend more time building new event streaming applications.
Automate key lifecycle operations
To extend the cloud-native operational model to Kafka, Confluent Operator also automates a couple of key lifecycle operations. The first is automated rolling upgrades, which keeps your platform current with version, configuration, and resource updates without impacting Kafka availability. The second is the ability to scale the environment more elastically by automating the addition and removal of Kafka brokers, Connect workers, KSQL nodes, and other components of the Confluent Platform.
Deploy on any platform, on premises or in the cloud
As you would expect, you can run Confluent Operator on build-your-own, open source Kubernetes. To give you more choice, we are also building an ecosystem of Kubernetes partners. If you are operating your own private cloud environment, on-premises or in the cloud, we support enterprise distributions such as Pivotal Container Service (PKS) via the Pivotal Services Marketplace, VMware Enterprise PKS via the VMware Solution Exchange, Red Hat OpenShift, Mesosphere Konvoy, and Mesosphere Kubernetes Engine.
If you prefer fully managed services in the cloud, Confluent Operator also supports services from all major cloud providers, including Google Kubernetes Engine (GKE), Amazon Elastic Kubernetes Service (Amazon EKS), and Azure Container Service (AKS).
Here’s a word from some of our partners:
“The use of microservices in modern software design has become widespread,” said Cornelia Davis, VP, Technology at Pivotal. “Pivotal fast-tracks adoption by integrating our cloud platform with enabling technologies like Spring Boot and Spring Cloud services to create a DevOps-friendly solution. The remaining challenge is in the data tier, because enterprises have a lot of data locked up in legacy stores. This is where event streaming architectures, now made easier with Confluent Platform on Pivotal Container Service (PKS), can help enterprises unlock even more value.
“A successful platform ecosystem designed to ensure customers avoid vendor lock-in is key to customer success when it comes to digital transformation,” said Jennifer Lin, Director of Product Management for Anthos at Google Cloud. “By offering Confluent Platform deployed via Confluent Operator on Anthos with seamless Google Kubernetes Engine integration, we have given customers an easy way to build and manage modern hybrid applications, and leverage Google Cloud’s differentiated infrastructure.”
Run at scale with confidence
Confluent Operator operationalizes years of experience running Kafka on Kubernetes at massive scale as part of our managed service, Confluent Cloud. This means you will experience a proven, battle-tested solution that you can deploy without deep Kubernetes expertise.
If we had you excited about adding automation to your Kafka deployments on Kubernetes, but you are running a non-containerized environment, we still have good news.
Production-ready Ansible Playbooks for Confluent Platform
Confluent has offered open source Ansible playbooks for some time, but they were not officially supported. Confluent Platform 5.3 includes enhancements to offer open source, fully supported, production-ready Ansible Playbooks that provide a simple and automated way to deploy the platform. Here’s what you can look forward to:
- Improved documentation with detailed information about configuring Confluent Platform
- Support for CA-based TLS certificates with two-way TLS mutual authentication
- Support for SASL GSSAPI (Kerberos) for authentication
- Added backward compatibility: deploy two major versions backwards from the latest major release
With Confluent Operator and Ansible, we are simplifying how you deploy production-ready environments. Now, let’s discuss how to simplify your management experience.
Simplify management across user interfaces
Users of Apache Kafka vary widely in their roles and needs. This is why we are actively investing in providing a complete set of user interfaces that fit you and your way of working.
Redesigned Confluent Control Center user interface
Control Center has rapidly improved ever since Confluent Platform 5.0, introducing features like consumer lag, a message browser, Schema Registry integration, the KSQL UI, dynamic broker configuration, and several more. This time, we decided to rethink what a great GUI to Kafka would look like and how it could make working with Kafka far easier.
Informed by dozens of customer interviews and user research sessions, Confluent Platform 5.3 delivers a completely redesigned user interface for Confluent Control Center that caters to your specific needs, whether your primary focus is operating a Kafka cluster or developing applications on it. If you’re focused on operations, you’re probably thinking about the hard work of making sure performance and availability SLAs are met. If you’re building applications, you’re more likely to want to inspect messages, create topics, change schemas, deploy connectors, and develop KSQL queries. If you live the DevOps life, you might be doing all of these.
Regardless, the redesigned UI offers a more cohesive and logical experience that will help you build the right mental model about the state of the platform and the data flowing through it. The end result is that it’s easier to understand, manage, and troubleshoot Kafka at scale.
If you are running a hybrid environment, you will also be excited to learn that the new UI offers a consistent user experience, whether you are running Confluent Platform on-premises or using our fully managed service, Confluent Cloud.
Although this is a complete redesign, here are just a few highlights:
- New homepage: provides a global view of the health of all your clusters and connected services
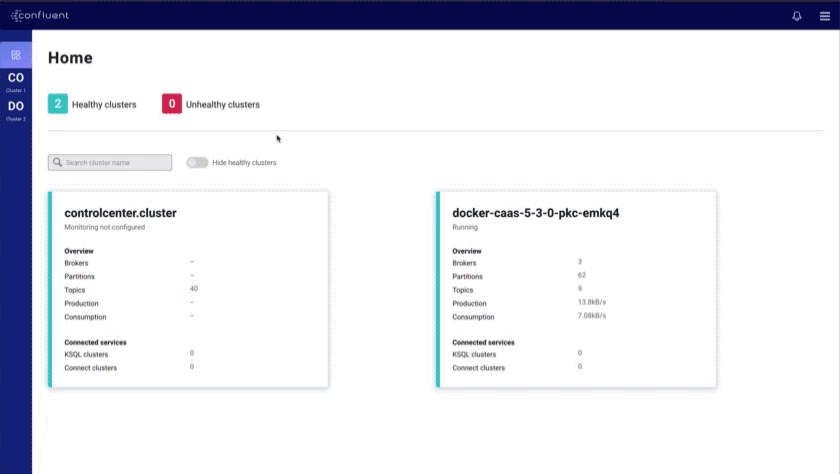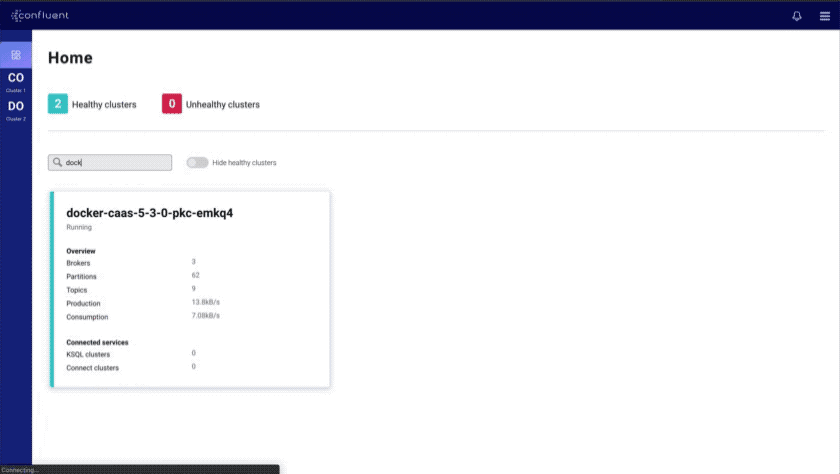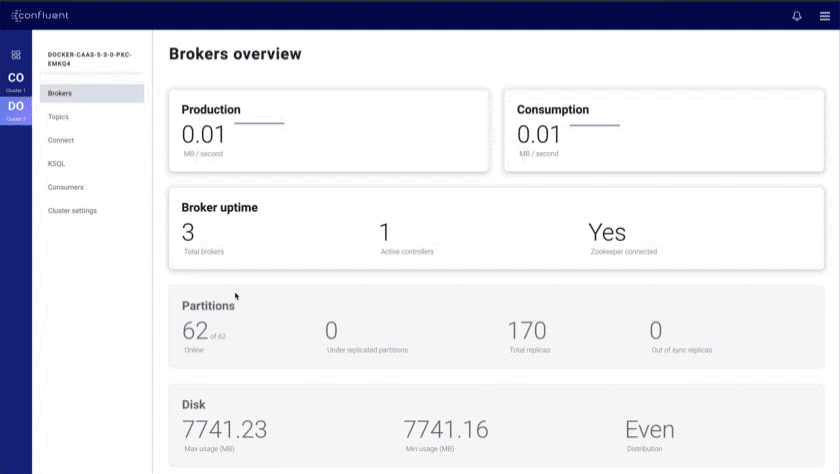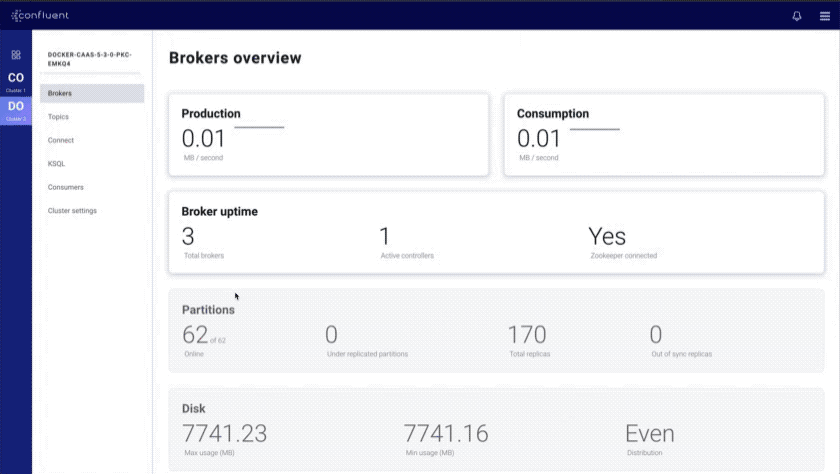
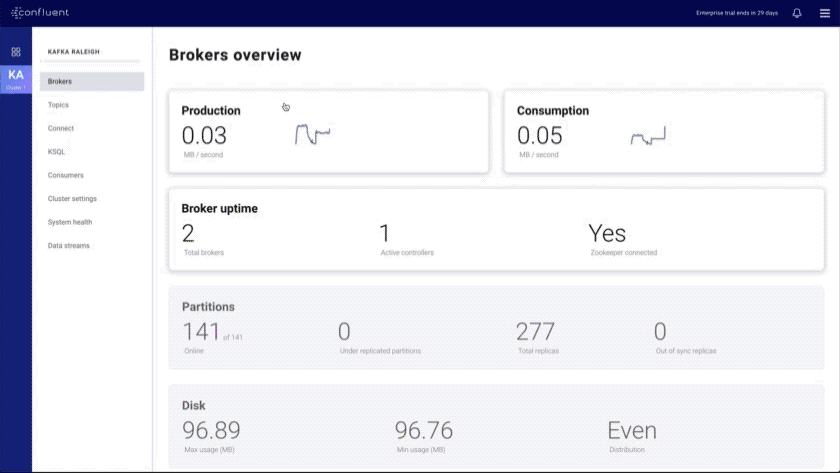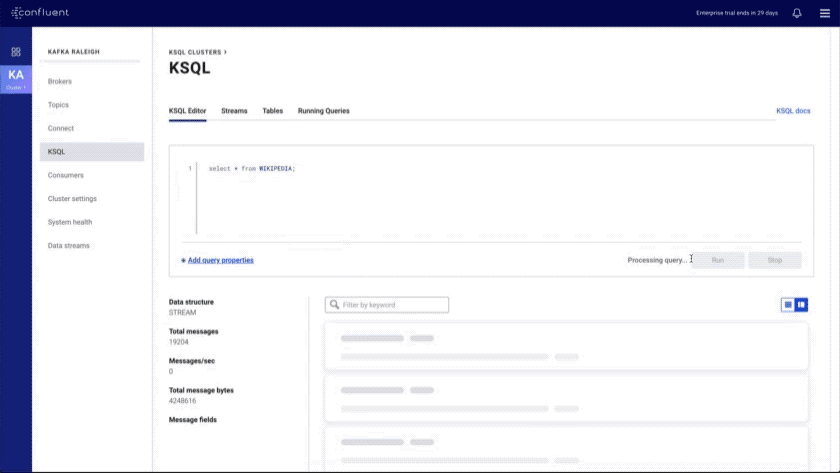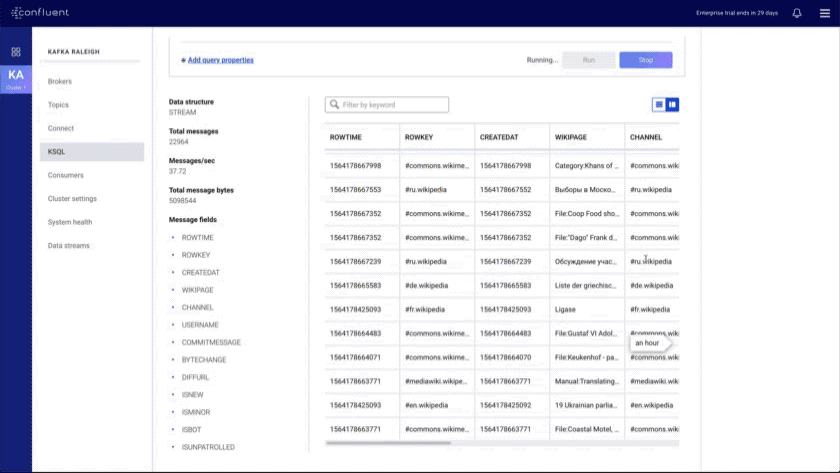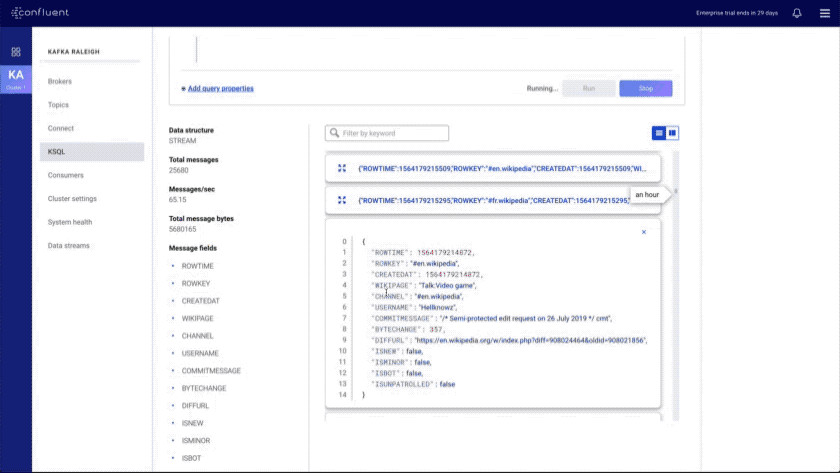
- Brokers overview: provides an at-a-glance view of key Kafka metrics
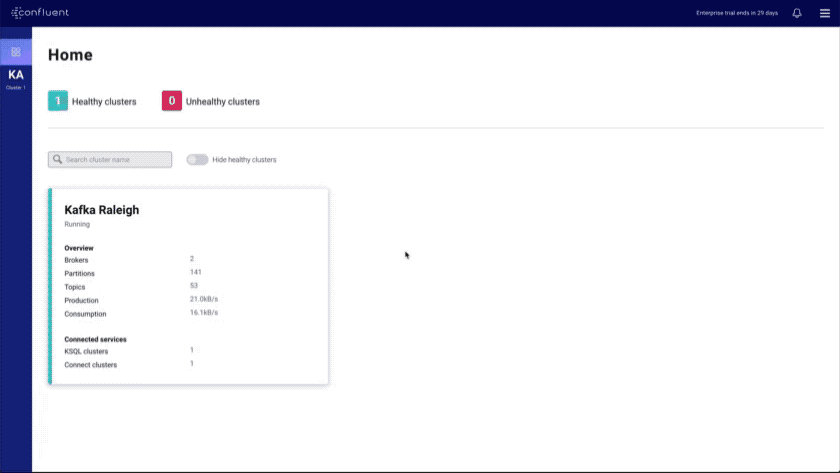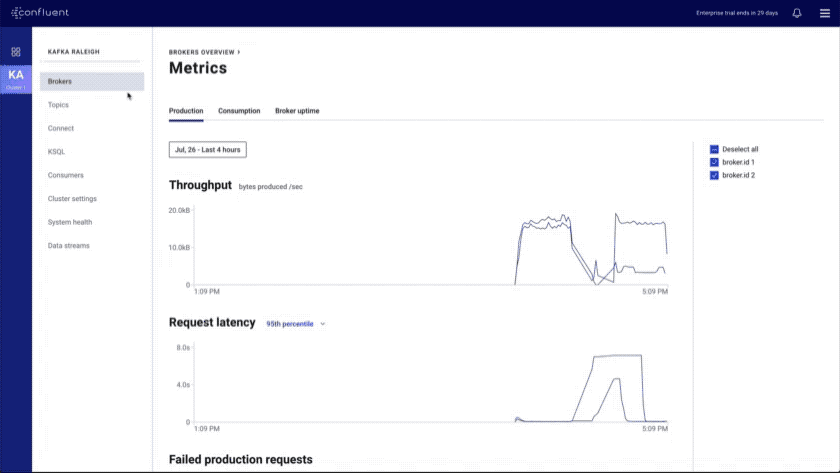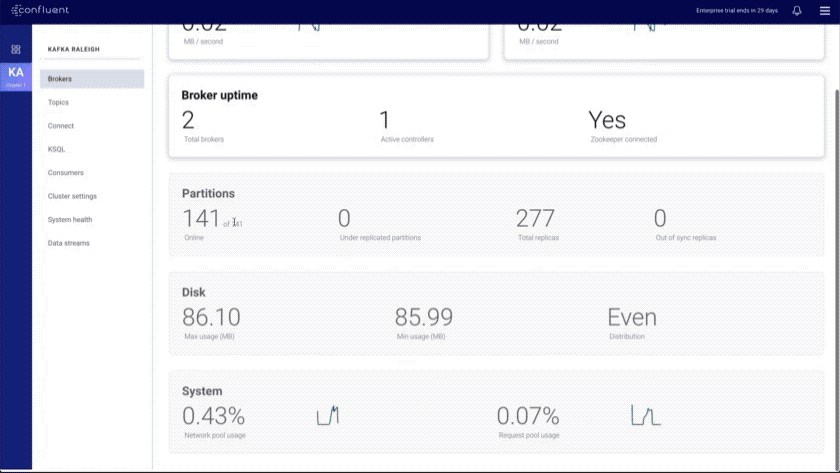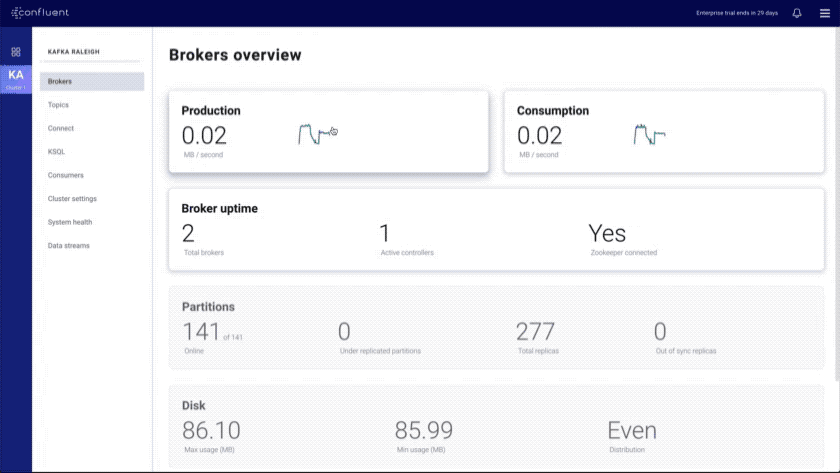
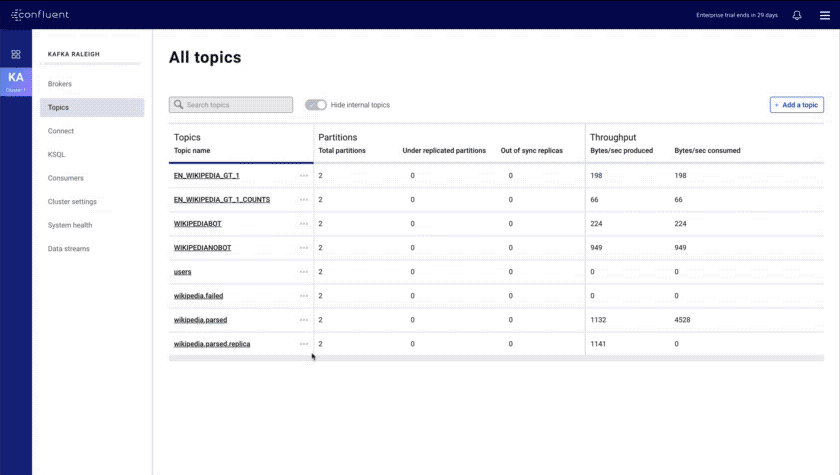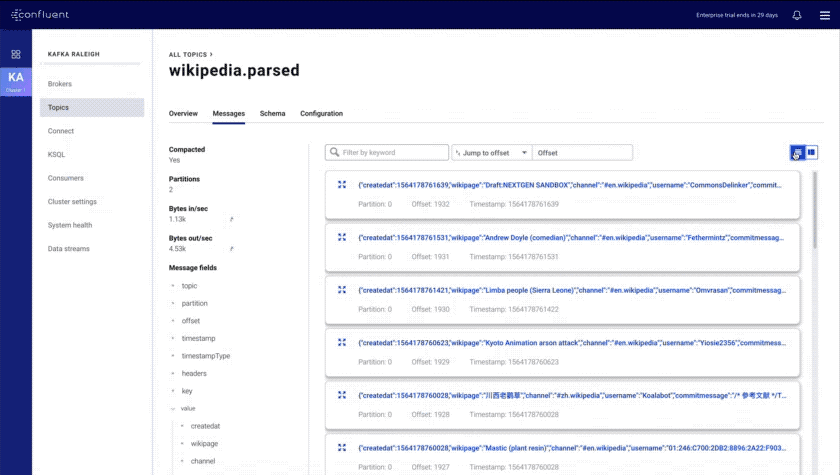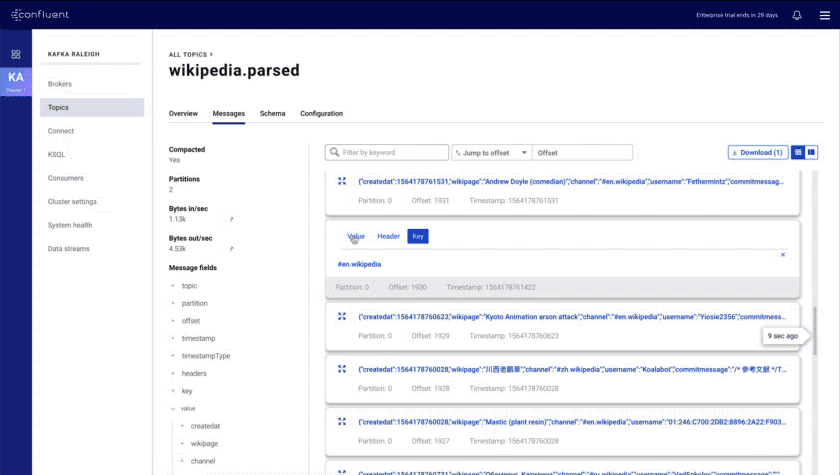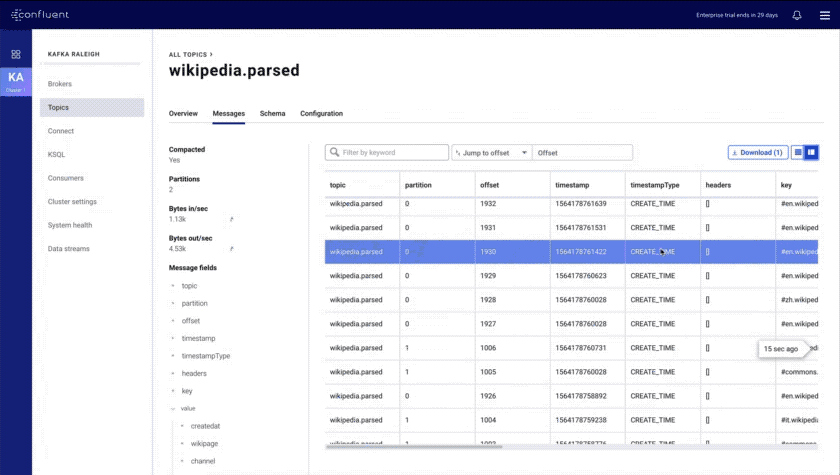
- Topics index and overview: shows all topics in the cluster and provides a topic overview that includes a health rollup
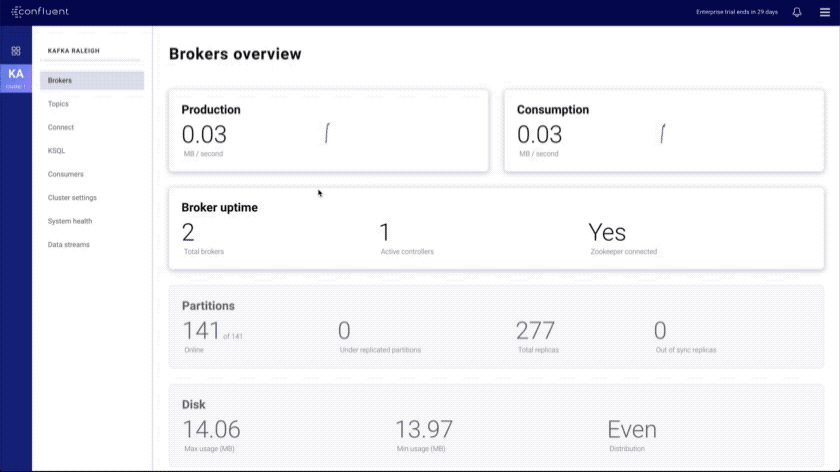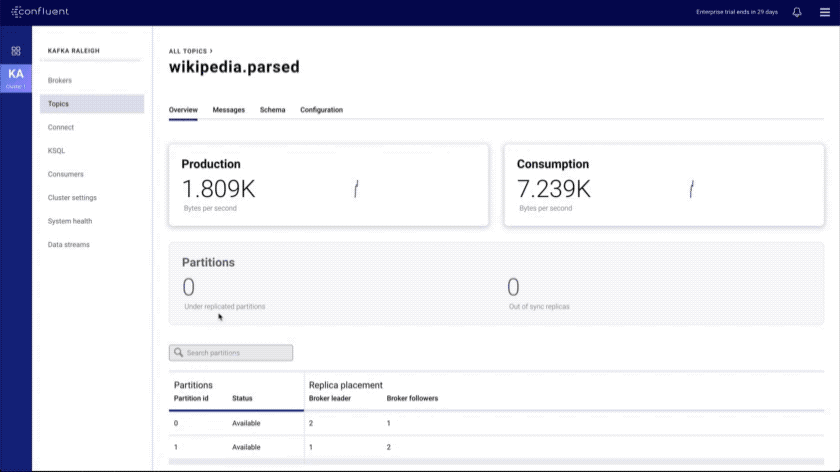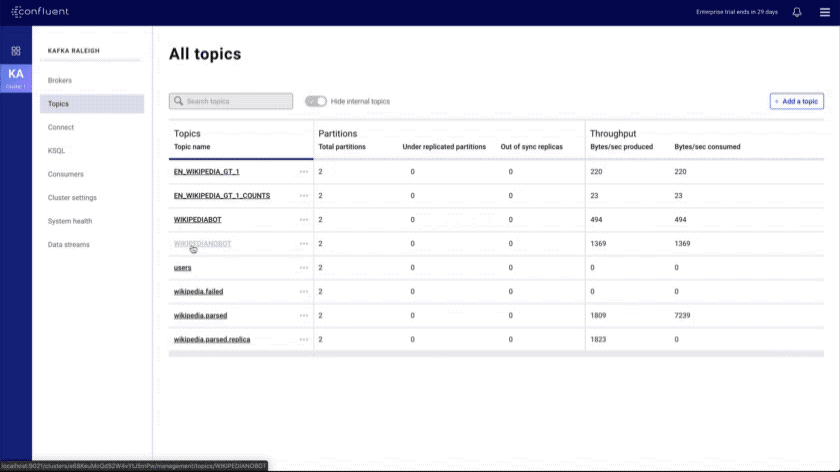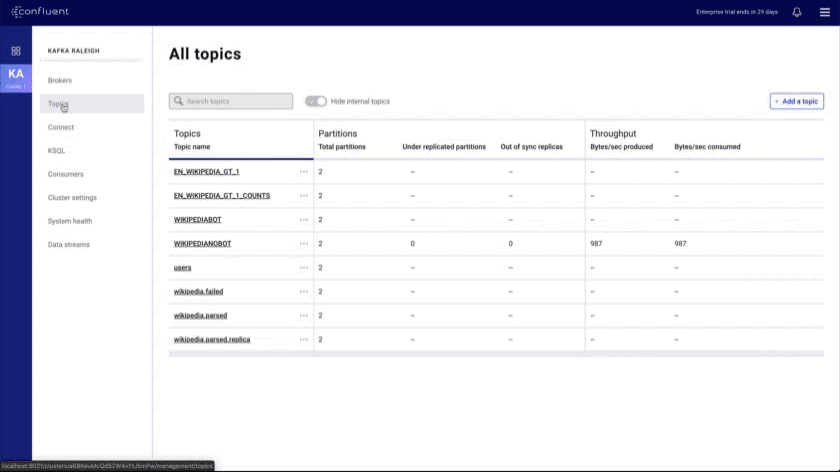
- Improved message browser: eliminates throttling and message loss, enables search by offset or timestamp from head to tail per partition, and allows you to download messages
- Connect and KSQL indexes and overviews: provides an overview of all Connect and KSQL clusters with search capabilities
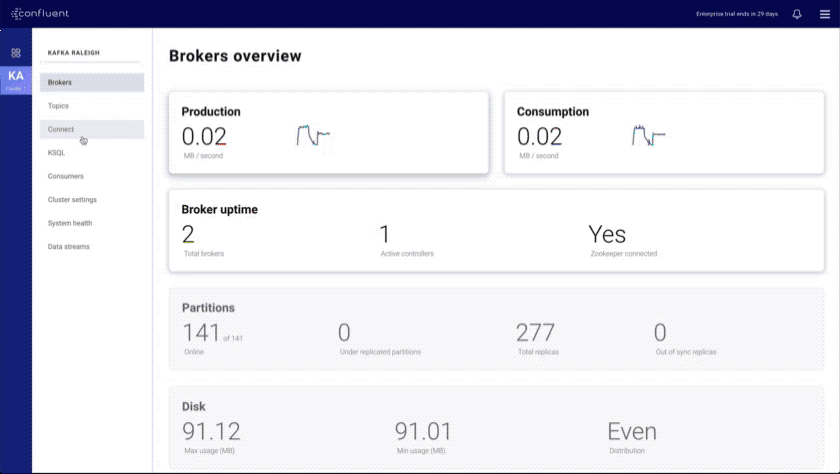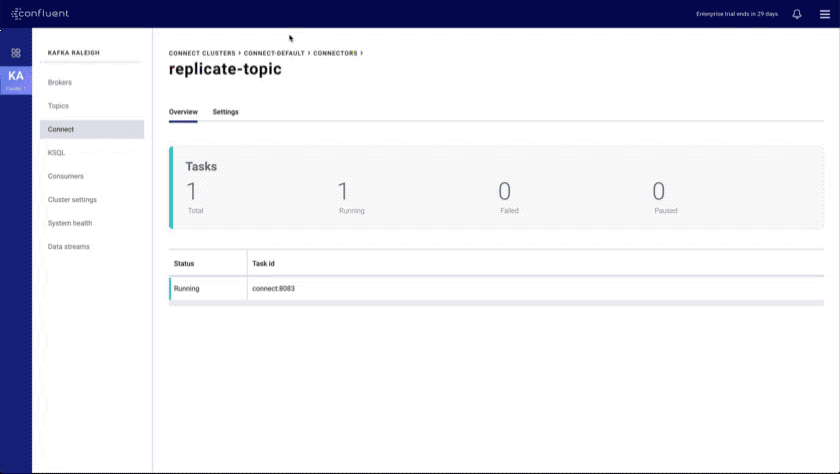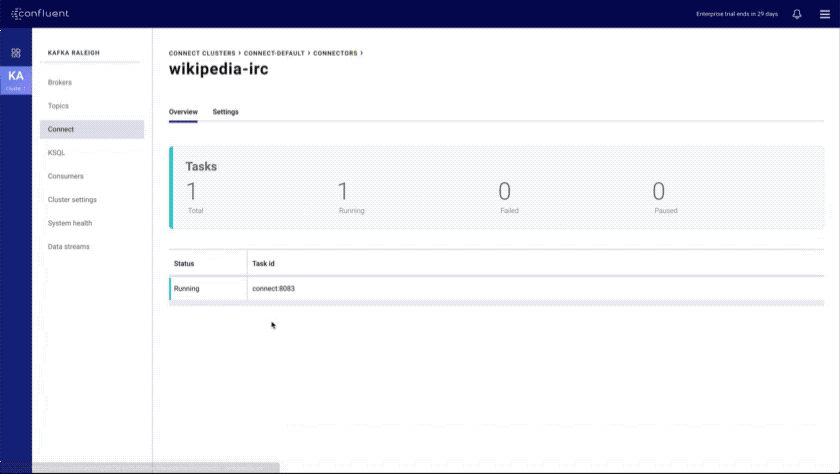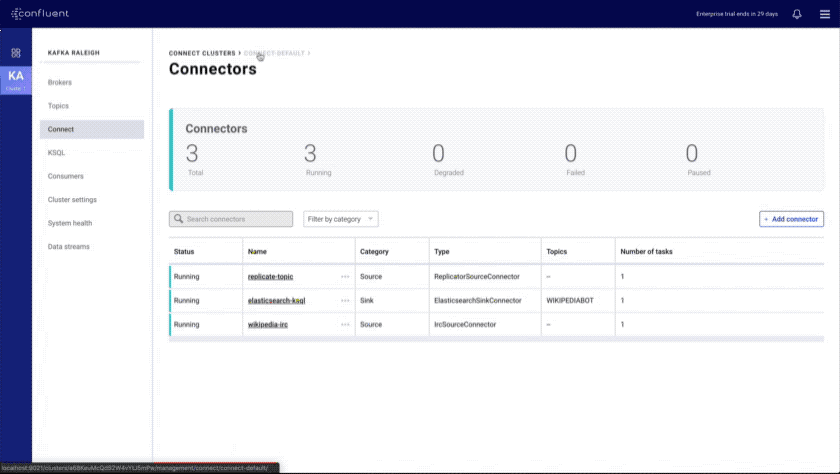
- Improved KSQL UI: introduces a data discovery side panel with click-to-SELECT and a resizable editor
We aim to provide a complete set of software interfaces, and this also includes a well-designed CLI.
New Command Line Interface
The previous version of the Confluent Platform Command Line Interface (CLI) was strictly for development use. We know from our own experience that you need a single, unified piece of command line tooling to handle common tasks across the development and deployment of an enterprise-grade system. This is why Confluent Platform 5.3 introduces a new production-ready CLI, fully supported by Confluent.
If you’ve gotten used to the previous CLI, don’t worry! The new CLI will allow you to perform all the same operations and more, all with very similar syntax.
Now that we have covered how Confluent Platform 5.3 provides automated deployments and simplified management, it’s time to look at how it makes your platform fundamentally more secure.
Secure the platform end to end
A comprehensive security strategy involves ensuring access to resources in a way that is simple enough to reason about, yet flexible enough to implement your organization’s security policies with precision. As your usage of event streaming increases, you may need to grant access to tens or even hundreds of users. This includes not just Kafka, but also Connect, KSQL, Schema Registry, and so on, and it requires a new way of thinking about authorization
Introducing the preview of Confluent Role-Based Access Control
We are very excited to deliver a preview of Role-Based Access Control (RBAC) for development environments. To provide secure authorization not just by user but by group as well, RBAC uses a set of seven predefined roles that help reassign the responsibility of managing permissions and access to the true resource owners, such as departments and business units.
RBAC authorization is comprehensive, enforced via all user interfaces (Control Center, new CLI, and APIs) across all Confluent Platform components (Connect, KSQL, Schema Registry, REST Proxy, and MQTT Proxy). On Kafka Connect clusters, we went one step further to provide connector-level access control. This will let you run secure Connect clusters shared across departments, while optimizing your resource utilization through multi-tenancy. RBAC provides tight integration with Active Directory and LDAP, so you can have a centralized way of configuring authentication and authorization for the entire platform.
RBAC will simplify large scale user/group authorization management across all Confluent Platform resources. We are introducing RBAC in preview right now, so please try it out in your development environment and feel free to provide feedback.
Introducing Confluent Secret Protection
Security compliance often requires that services do not store secrets as cleartext in files. These secrets may include passwords, or any other sensitive data in configuration files or log files. The best approach to this problem is to encrypt secrets directly, so that they are never stored in cleartext. Confluent Platform 5.3 introduces a Secret Protection feature that encrypts secrets within the configuration file itself and does not expose the secrets in log files. It extends the security capabilities introduced in KIP-226 for brokers and KIP-297 for Connect to enable end-to-end secret protection across all Confluent Platform components: Kafka brokers, Connect, KSQL, Schema Registry, Control Center, REST Proxy, etc.
New Confluent Server software package
To use Confluent Operator, the RBAC preview, or the LDAP Authorizer (this last feature was introduced previously with Confluent Platform 5.2), you need to deploy the Confluent Server software package. Confluent Server is a new, optional component of Confluent Platform that includes Kafka and additional software to enable these new features. You have the option of deploying Confluent Platform with the Confluent Server if you want to leverage RBAC, LDAP or Operator, or you can deploy with Apache Kafka if you don’t have a need for these features. If you are already a Confluent Platform user, you can easily migrate from Apache Kafka to Confluent Server and migrate back if required. For more information on how to migrate to the Confluent Server, see the documentation.
Built on Apache Kafka 2.3
As is standard for all of our releases, Confluent Platform 5.3 is built on the most recent version of Apache Kafka, which in this case is version 2.3. If you want to learn what’s included in 2.3, we have several resources available for you:
- Detailed blog post by Colin McCabe
- Video presentation by Tim Berglund
- Audio-only version of the video
Get started
With Confluent Platform 5.3, you can automate deployments, whether they are on-premises or in the cloud, using Confluent Operator and the production-ready Ansible Playbooks. You can more easily understand and manage your event streams with the redesigned Control Center interface and the new CLI. You can secure access to your entire platform without losing your mind using the Role-Based Access Control preview.
There are many more features in Confluent Platform 5.3 than what we cover here, which you can read about in the release notes. If you simply want to try them, download Confluent Platform 5.3.
Download Confluent Platform 5.3
You can also find a summary of what’s new in Confluent Platform 5.3 by checking out the podcast or video with Tim Berglund.
As always, we are happy to hear your feedback. Please post your questions and suggestions to the public Confluent Platform mailing list, join our community Slack channel, or contact us directly! We can’t make this the world’s best event streaming platform without you.
As usual, I want to thank everyone who contributed to this blog post: Mauricio Barra, Tim Berglund, Neha Narkhede, Praveen Rangnath, Justin Dorff, Raj Jain, Michael Ng, Vahid Fereydouny, Cheryle Custer, Angela Burke, and Victoria Yu.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...