コネクタープライベートネットワーキングの紹介 : 今後のウェビナーに参加しましょう!
How Merging Companies Will Give Rise to Unified Data Streams
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
Company mergers are becoming more common as businesses strive to improve performance and grow market share by saving costs and eliminating competition through acquisitions. But how do business mergers relate to event streaming?
Introduction
In order to gather feedback, improve product offerings, and evolve their business model over time, digital companies capture various business events in real time, such as customer interactions, payments, and much more. Let’s examine two specific examples.
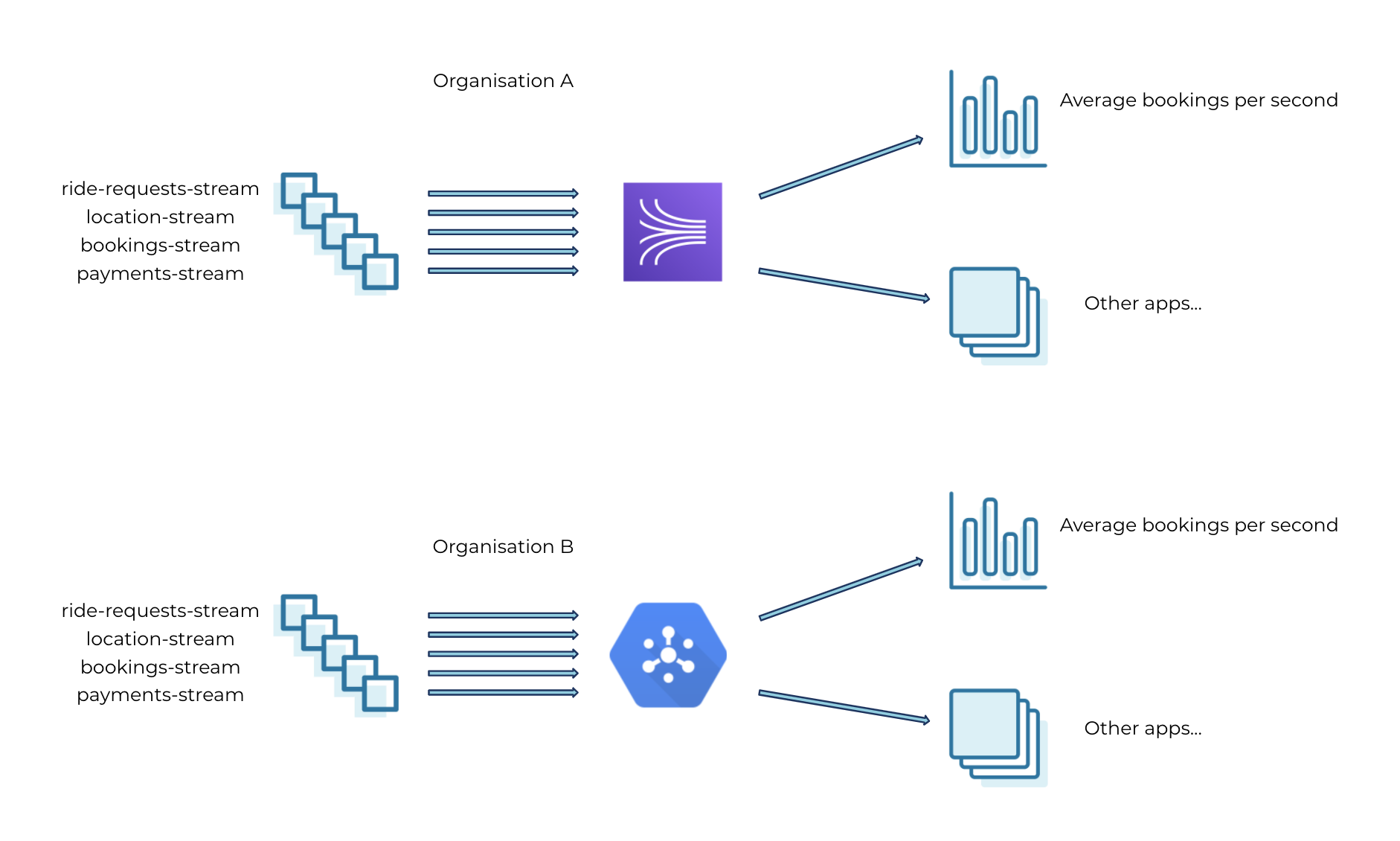
- Two ride-sharing companies merge to grow their market share and save costs.
- A larger gaming company acquires multiple smaller game studios for new IP and to expand their user base.
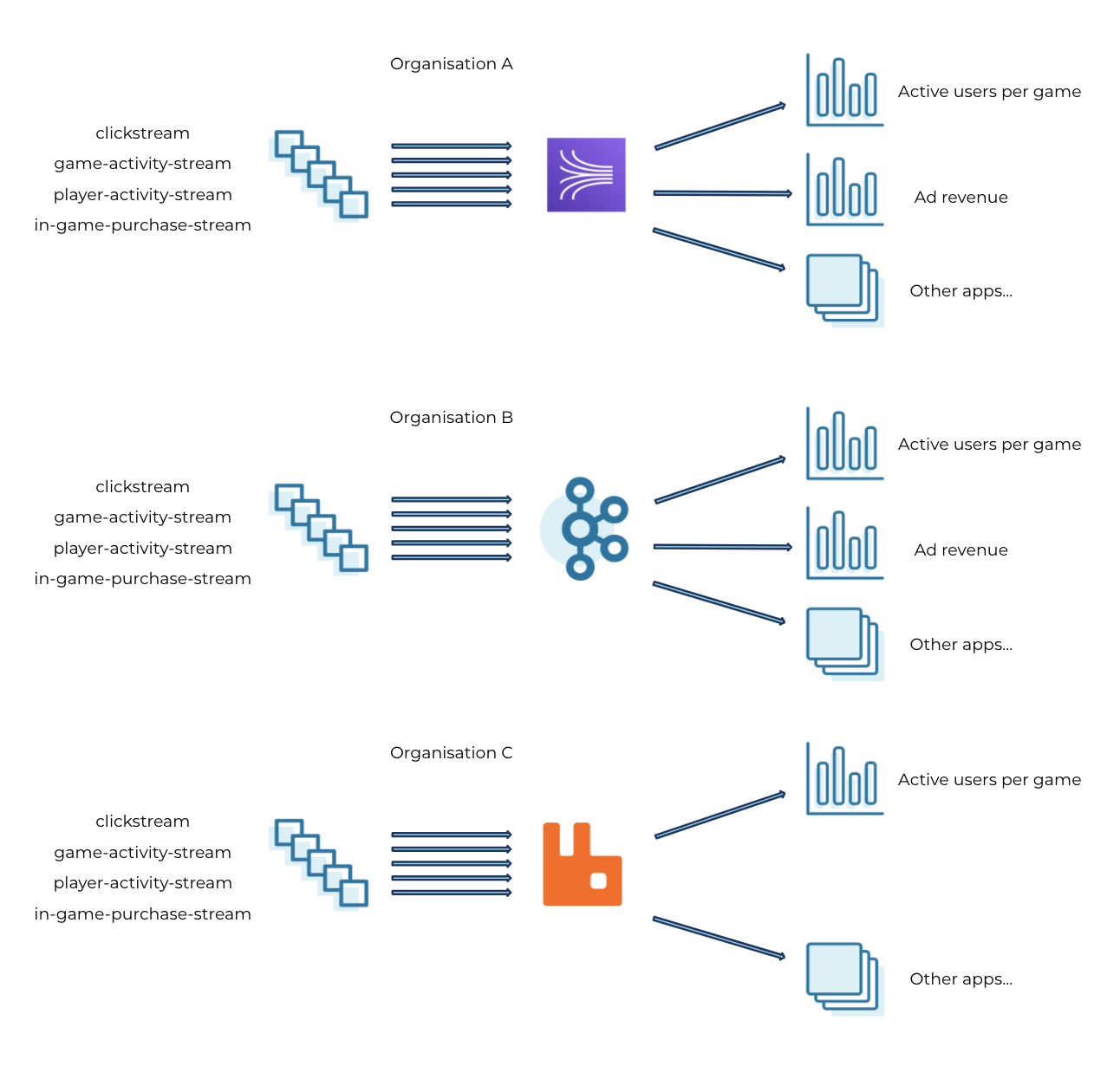
In both of these scenarios, each individual company has established data pipelines to capture business events in real time based on their preferred tools, deployment environment, and developer skills. As they merge, they face new challenges in unifying their respective data pipelines to cater to the increased scale and volume of the combined business. They also need to keep track of costs for managing and maintaining the pipeline, in addition to rewiring applications that leverage a new event streaming infrastructure.
This blog post looks at how Confluent Cloud and the connector ecosystem help with business mergers by reducing the time needed to integrate operational data pipelines and by unifying real-time data streams with close to zero downtime in operations.
Why unify data streams?
Digital companies are typically nimble and experiment continuously, with developers who focus on shipping features quickly and tend to use familiar tools or those that are available as a native service on the cloud provider where a majority of the workloads run.
When companies that run workloads in different environments merge, it’s challenging to pick a favourite event streaming tool of choice, decide who is going to manage it, and determine how best to integrate the various data streams.
Confluent Cloud provides a fully managed event streaming service built on Apache Kafka® that is easy to adopt, scalable, and familiar to developers. Confluent Cloud comes with a broad ecosystem of connectors that streamlines integration across existing platforms. Hence, bringing various data streams together through Kafka and unifying them on Confluent Cloud helps the business not only capture all events in one place but also continue to make operational decisions in real time, post merger.
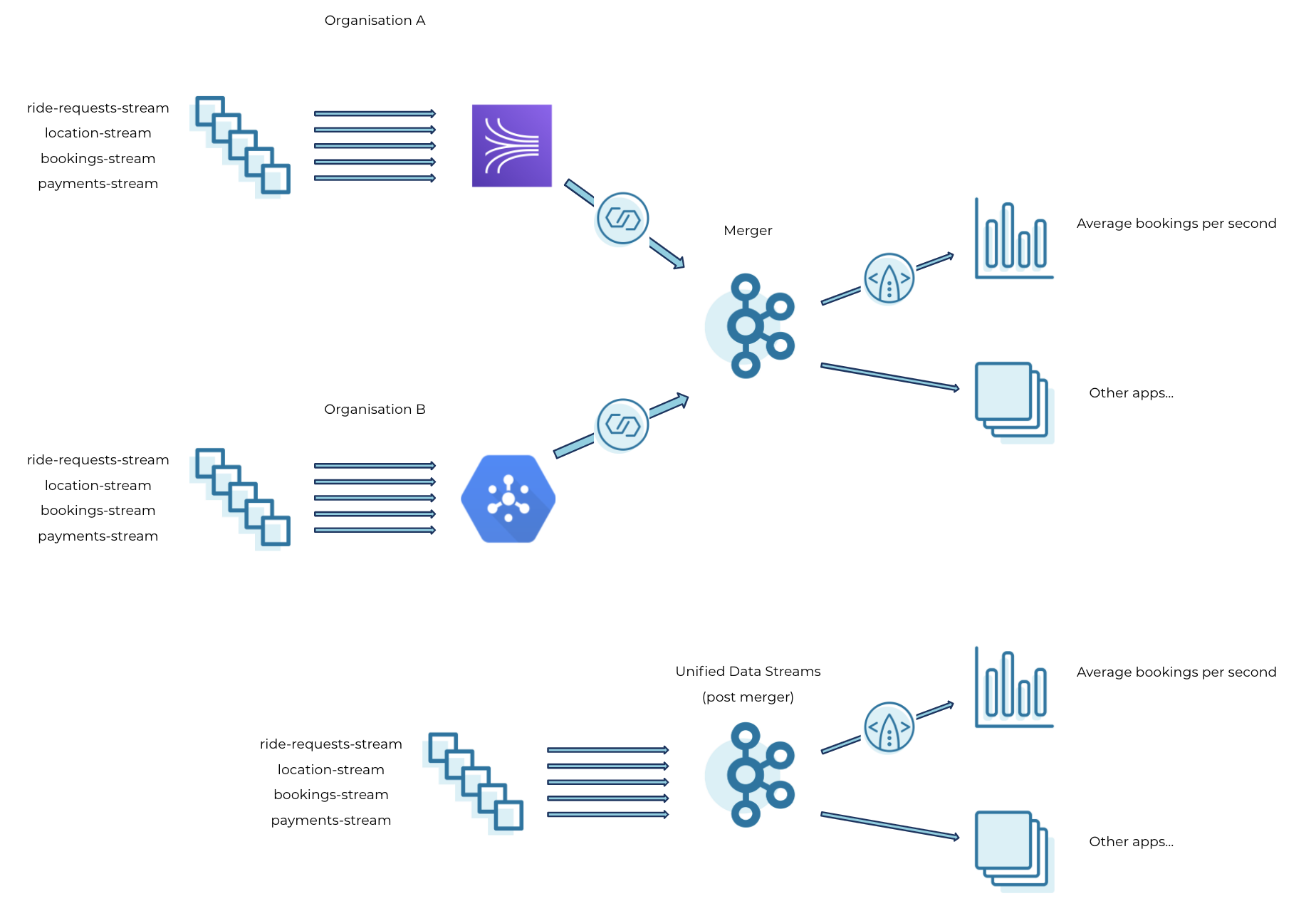
Going back to the merger scenario above, we now have a centralised Kafka cluster in place ready to take direct data streams from organisation A and organisation B. As soon as the merger is finalised, each of the ride-sharing companies (A and B) can use Kafka Connect to sink multiple, real-time data feeds into Confluent Cloud, merging the event streaming infrastructure onto a centralised Kafka cluster.
Additionally, with the help of fully managed ksqlDB, business metrics such as average bookings per second can continue to be computed in real time on the merged data streams, which represent the total volume of rides for both companies as opposed to being two individual pipelines. As a next step, the applications can slowly migrate to streaming events into the central Kafka cluster instead of two separate event streaming infrastructures.
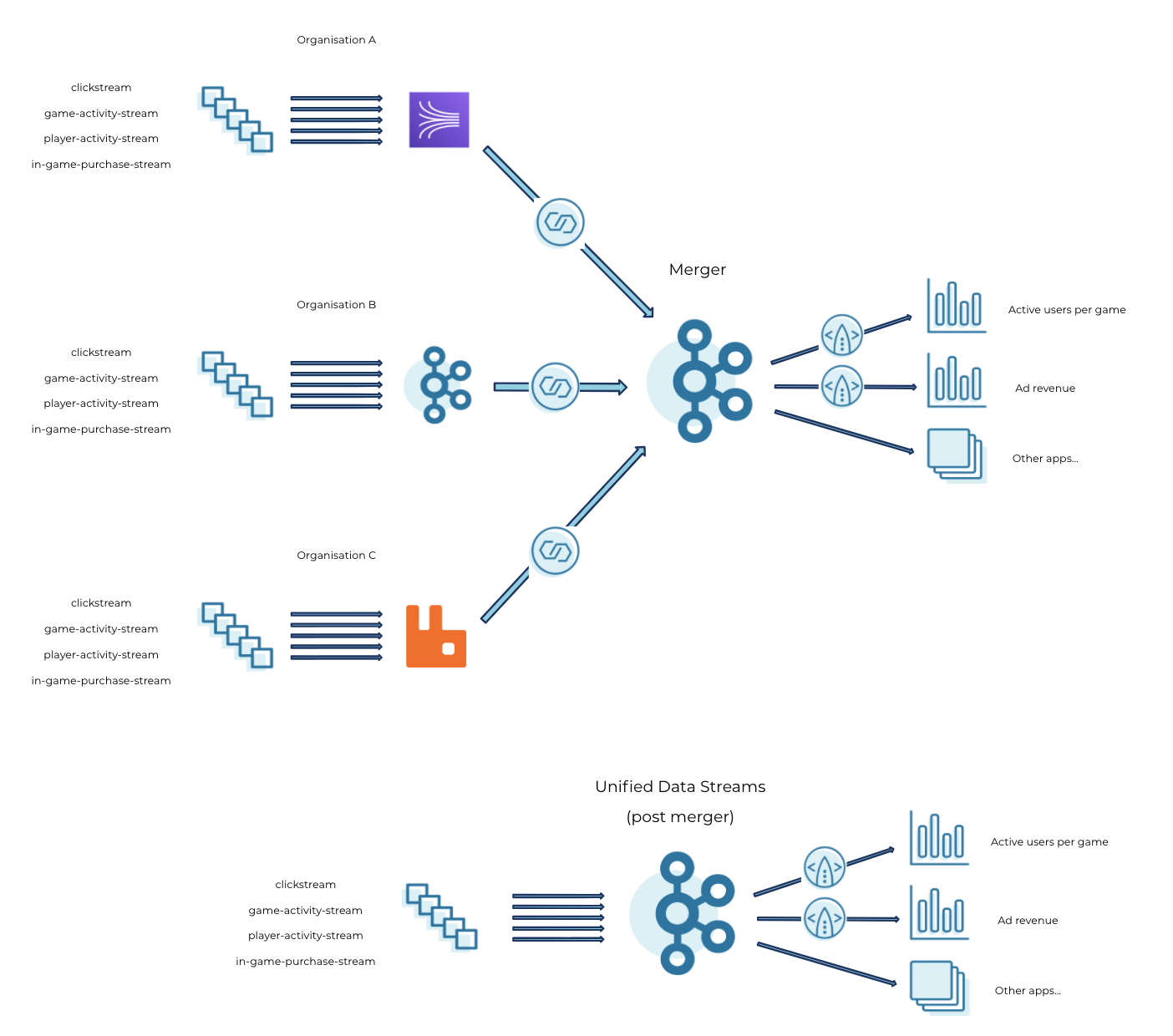
A similar approach can be taken for the gaming companies scenario, where each event streaming infrastructure can be incrementally merged into a central Kafka cluster on Confluent Cloud. Business metrics including active users per game, ad revenue, etc., can continue to be measured post merger without any operational disruption.
How is this done?
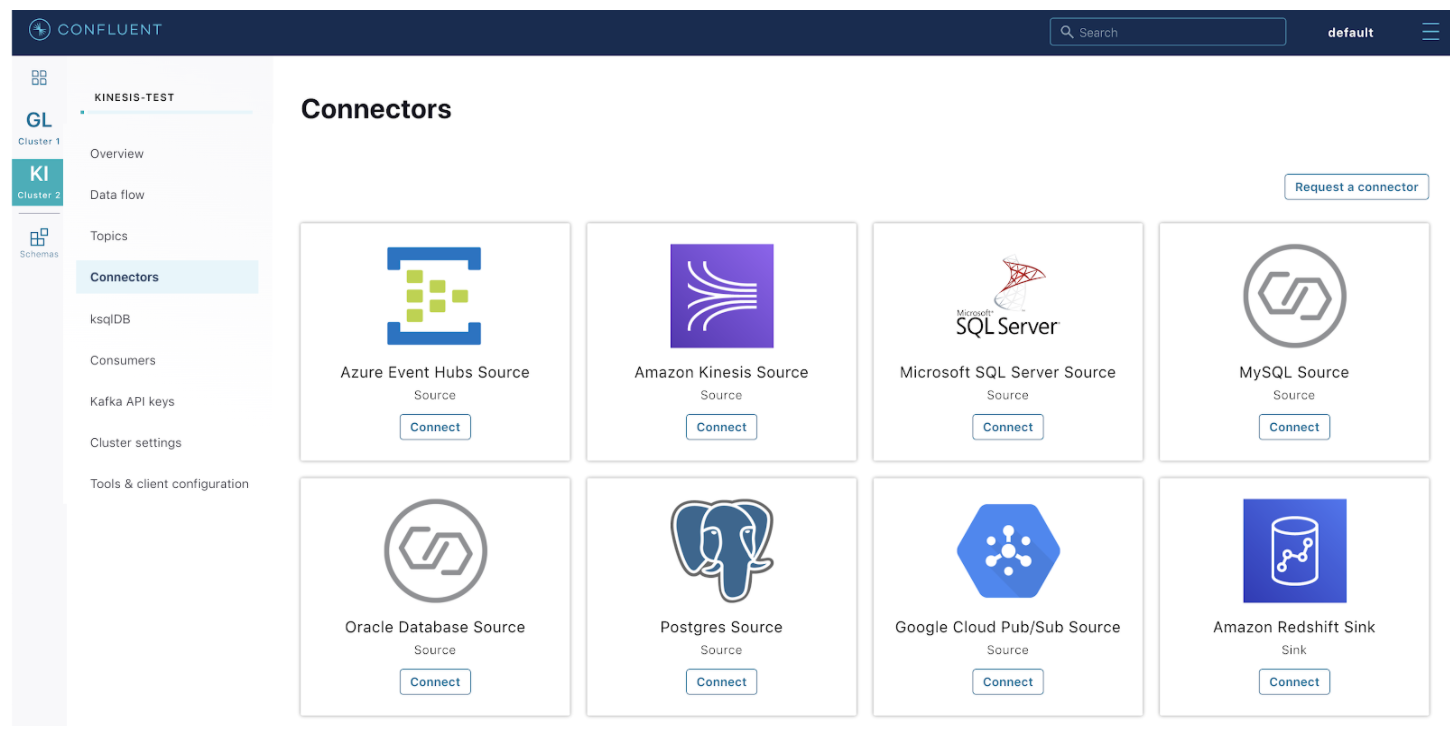
Let’s see how all this comes together with an example pipeline: getting a mock payments stream from Amazon Kinesis into Confluent Cloud using the fully managed Kinesis source connector.
Step 1: Create a Kinesis data stream through the AWS Management Console.
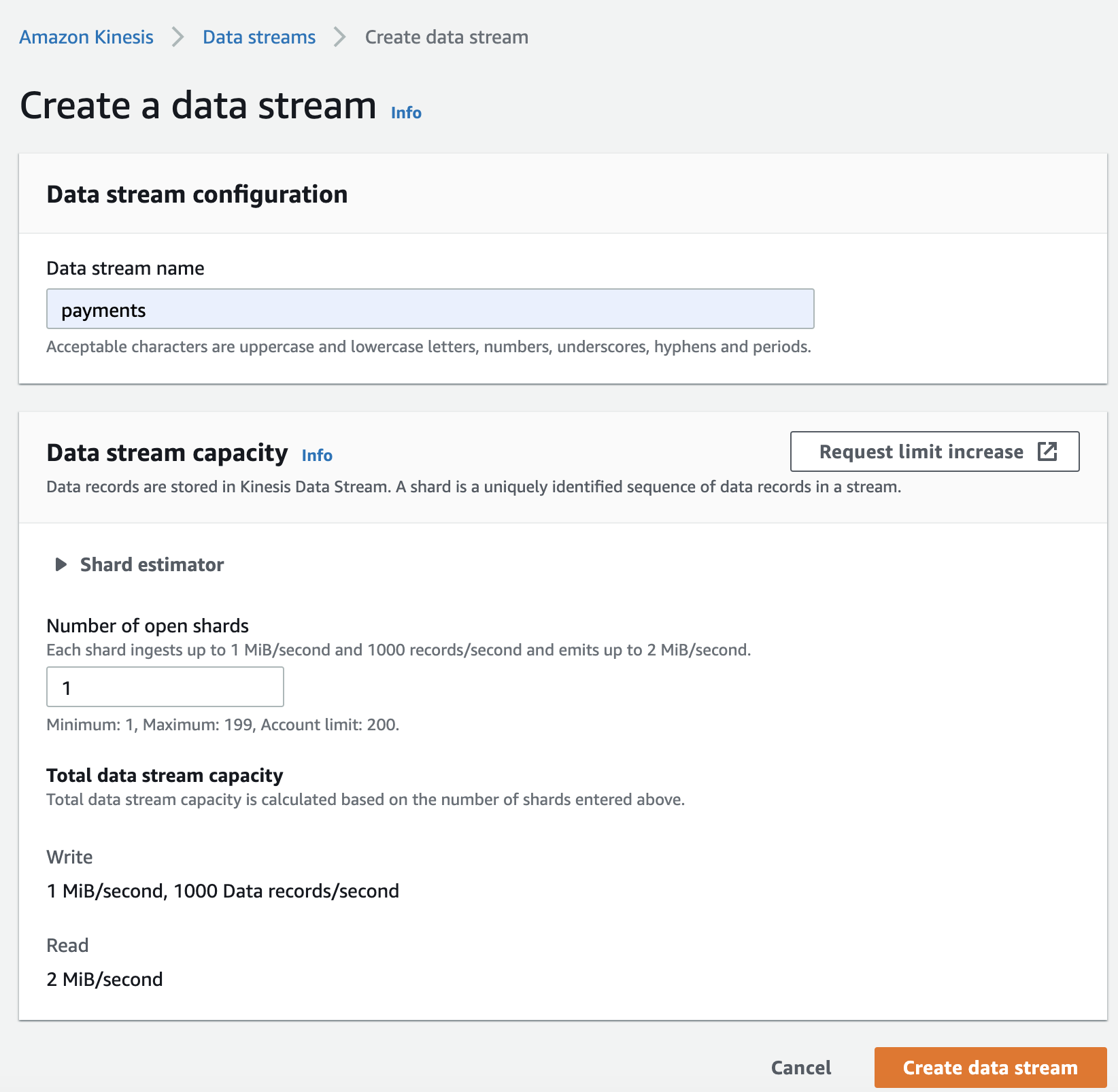
Step 2: Sign up/log into Confluent Cloud and provision a Confluent Cloud cluster.
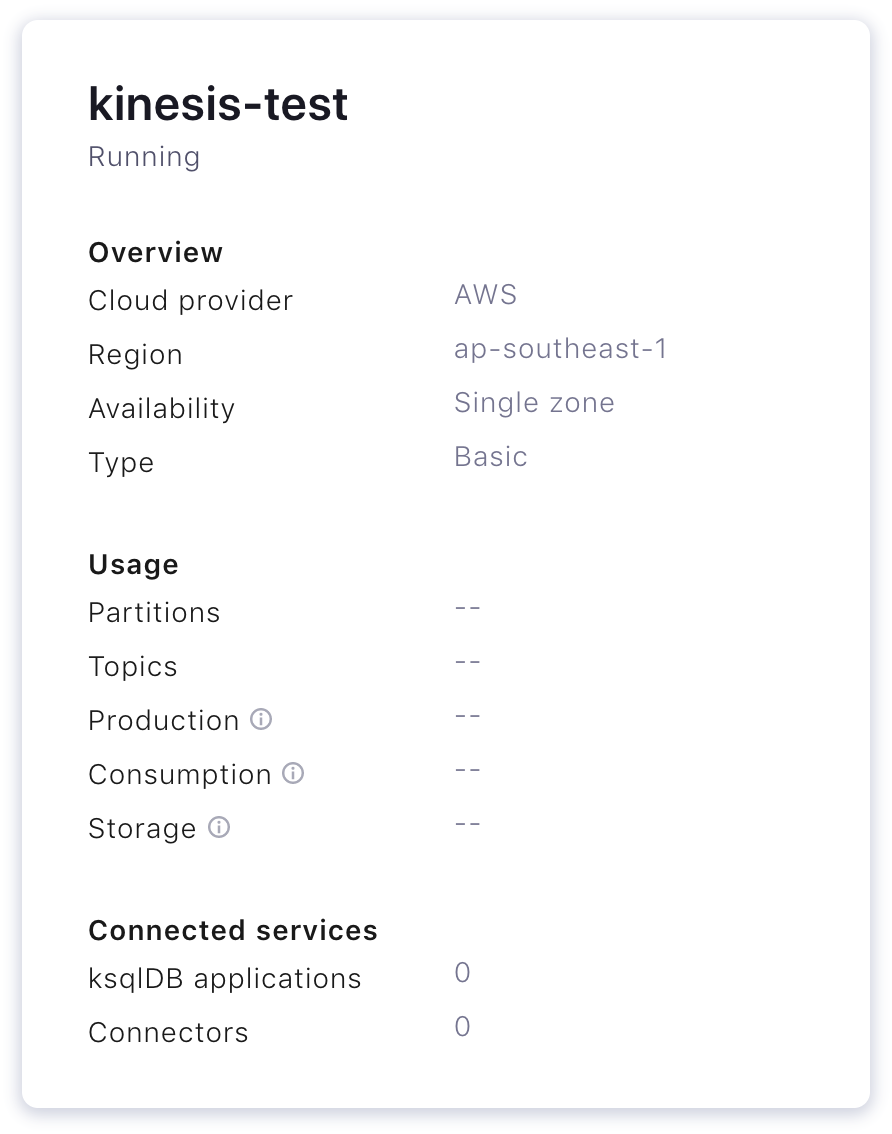
Step 3: Create a Kafka topic to receive data from Kinesis.
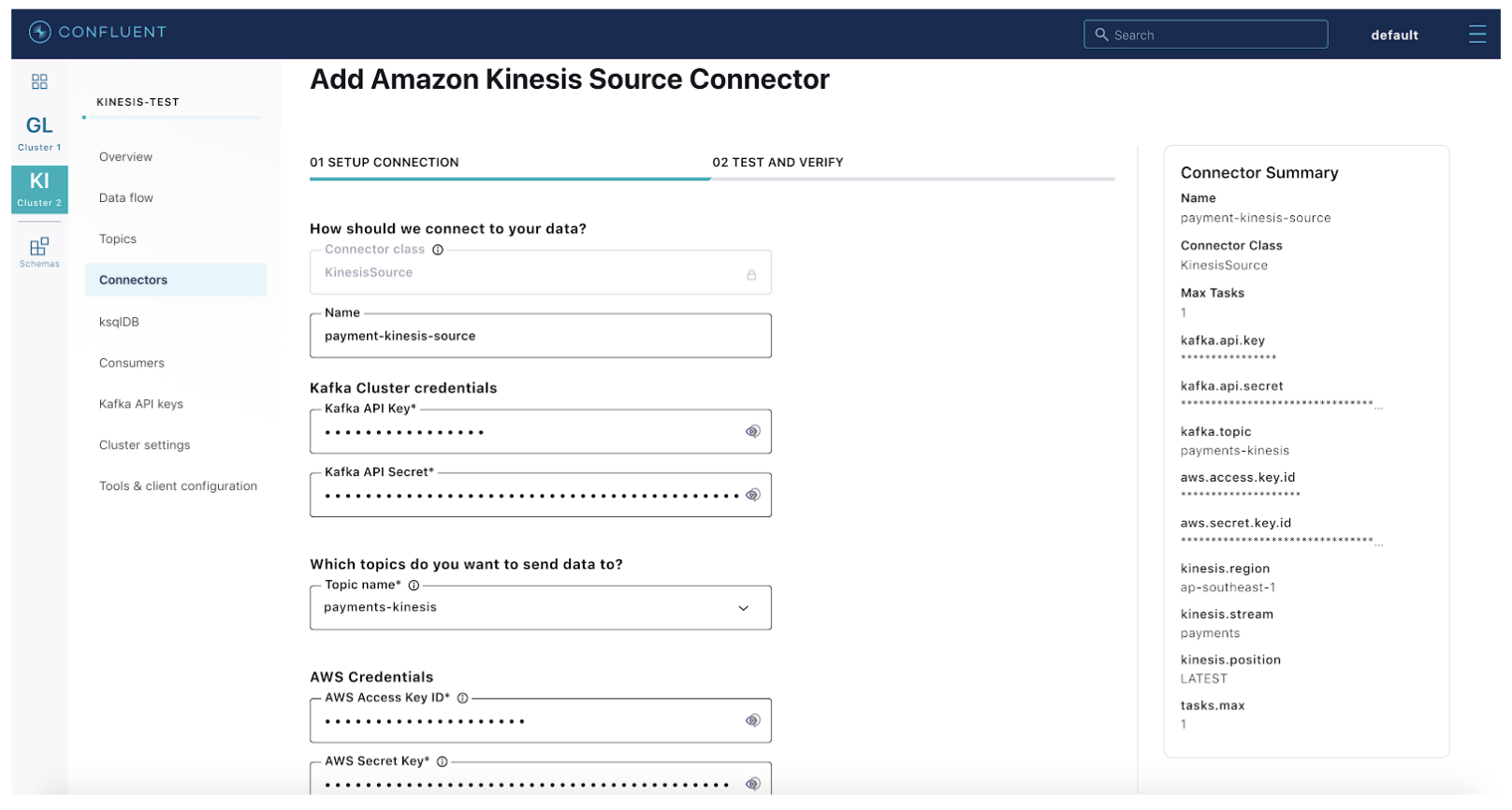
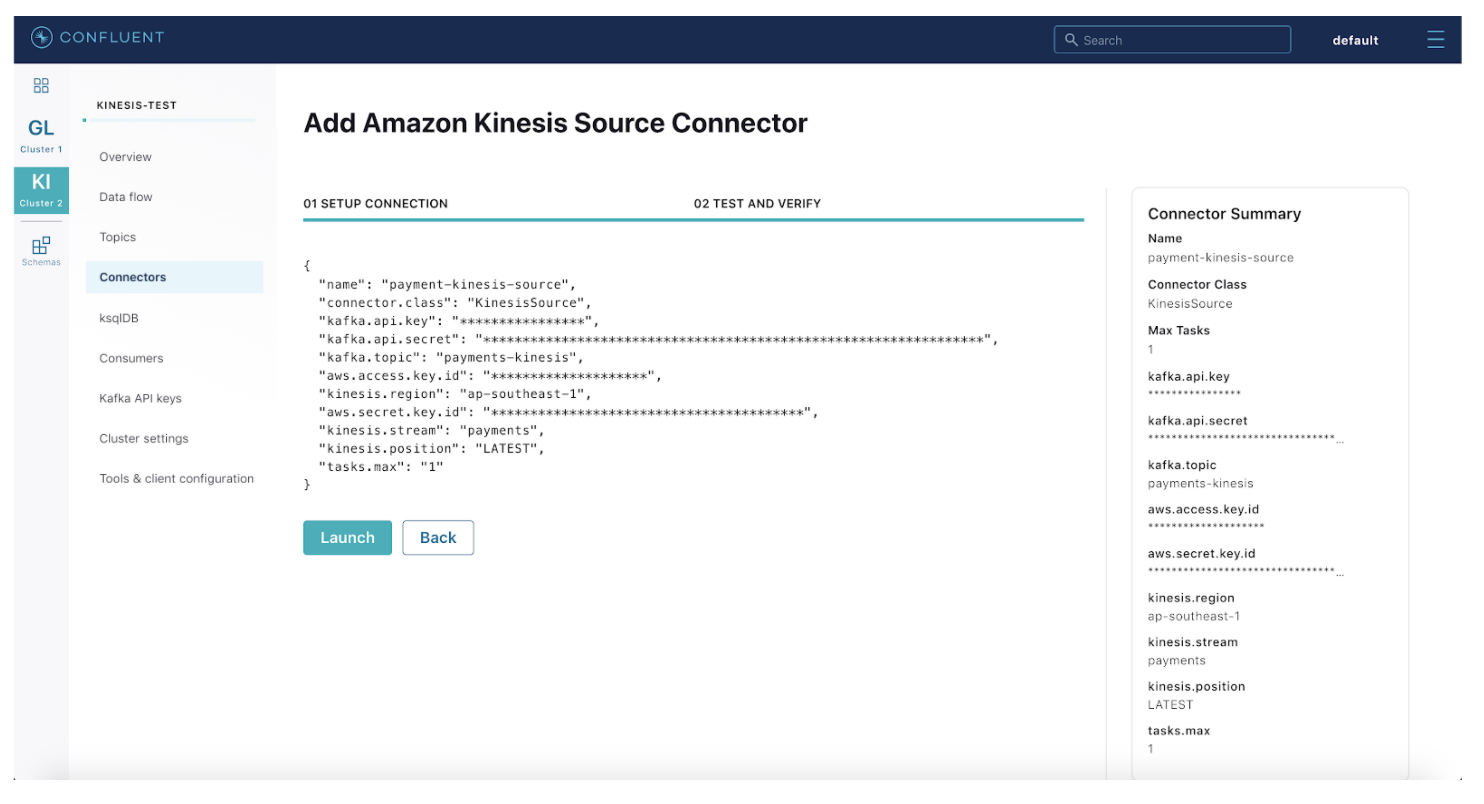
Step 4: Configure and launch a fully managed Kinesis source connector on Confluent Cloud.
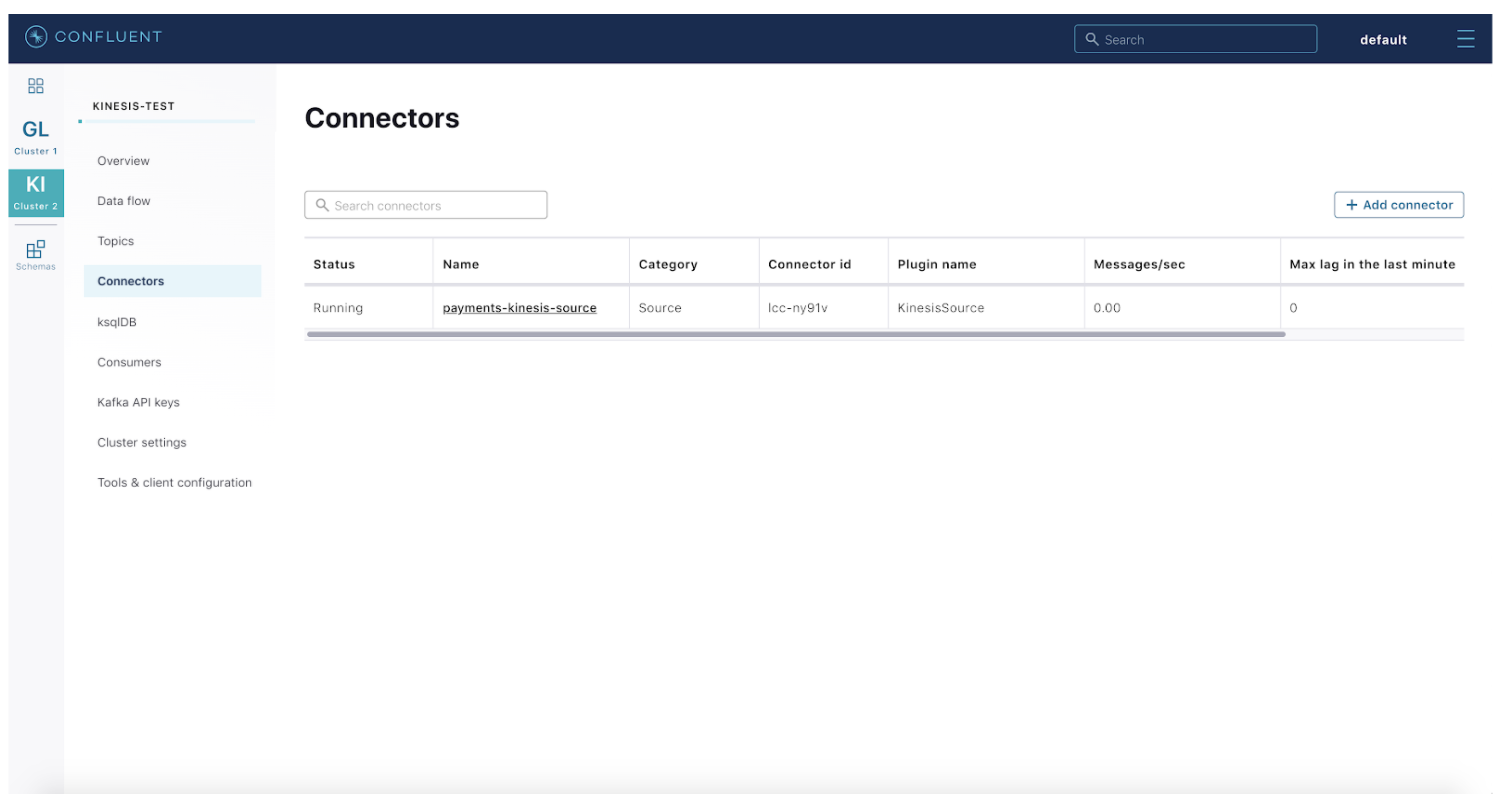
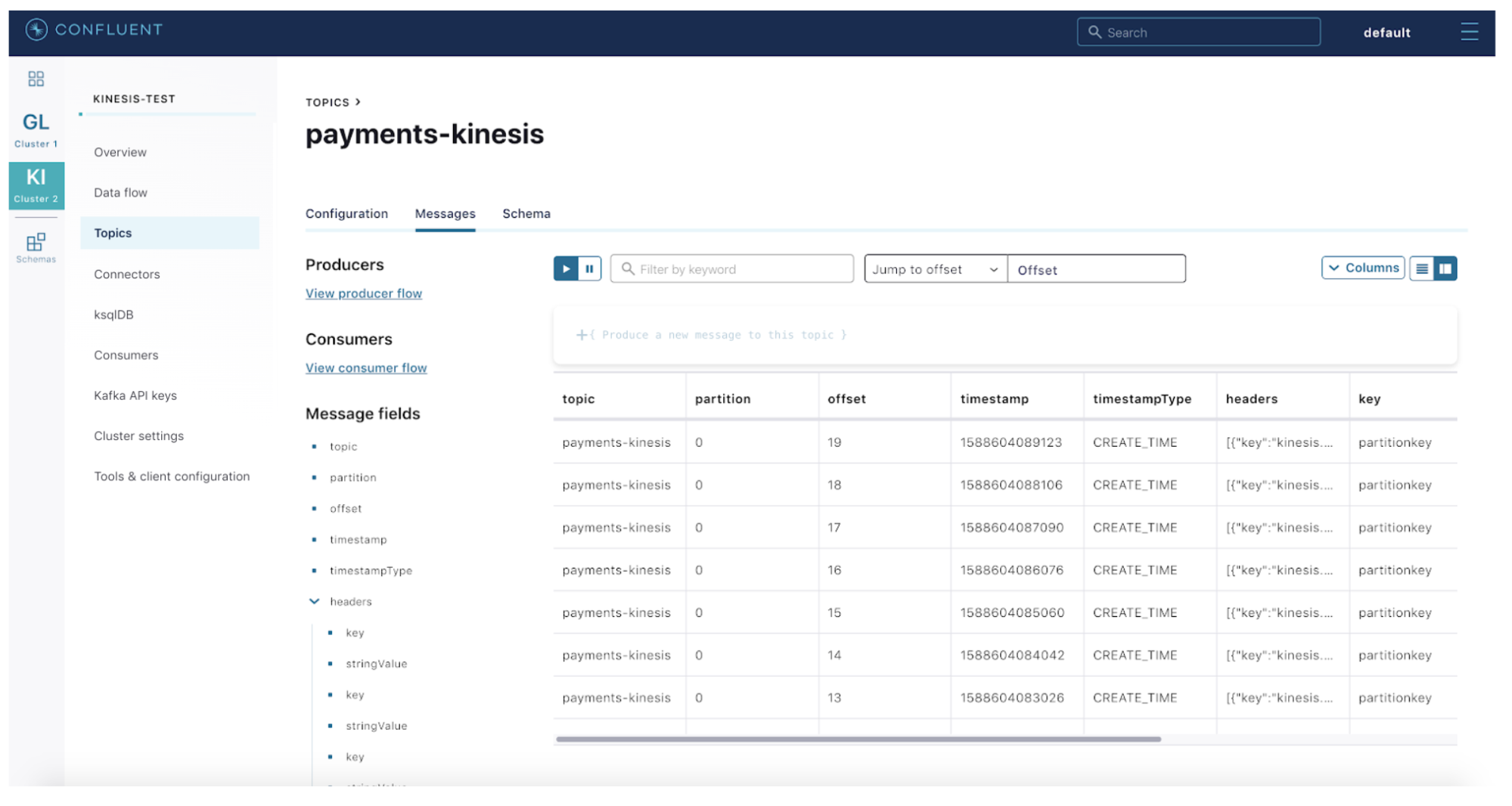
Step 5: Open the Confluent Cloud message browser, and navigate to the payments-kinesis topic. Start producing messages into Kinesis using the sample Python script below to see the data flow from Kinesis to Confluent Cloud:
from boto import kinesis import testdata import datetime import json import time
class Users(testdata.DictFactory): custid = testdata.RandomInteger(1, 10) amount = testdata.RandomInteger(1, 100) gateway = testdata.RandomSelection(['visa', 'paypal', 'master', 'stripe', 'wallet'])
if __name__ == '__main__': kinesis = kinesis.connect_to_region("ap-southeast-1") print kinesis.describe_stream("payments") print kinesis.list_streams()
for user in Users().generate(10): print(user) print kinesis.put_record("payments", json.dumps(user), "partitionkey") time.sleep(1)
Summary
Through this blog post, we walked through the concept of unifying data streams using Confluent Cloud and looked at a specific example of integrating a Kinesis data stream using the fully managed Amazon Kinesis source Kafka connector.
Sign up for Confluent Cloud, provision a Basic cluster, and try this out now! You can use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage.* Also make sure to check out the Cloud ETL demo for hybrid and multi-cloud pipelines. Should you have questions, Confluent Community Slack is the place to go.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Schema Registry Clients in Action
Learn about the bits and bytes of what happens behind the scenes in the Apache Kafka producer and consumer clients when communicating with the Schema Registry and serializing and deserializing messages.

How to Securely Connect Confluent Cloud with Services on Amazon Web Services (AWS), Azure, and Google Cloud Platform (GCP)
The rise of fully managed cloud services fundamentally changed the technology landscape and introduced benefits like increased flexibility, accelerated deployment, and reduced downtime. Confluent offers a portfolio of fully managed...