To get additional metadata from our network devices, including things like the access point and user device names, we’re going to stream this data from its source into Kafka. Ubiquiti uses MongoDB to hold this data, and there’s a great change-data-capture (CDC) tool built on Kafka Connect called Debezium that supports several source databases—including MongoDB! We can use this to stream the current contents of the database into a Kafka topic, as well as all and every subsequent changes to that data. This means that in effect we maintain a live mirror of our MongoDB database in Kafka itself. We don’t need to do some kind of convoluted lookups from Kafka out to a database each time we want to look up some reference data, since we have now that reference data within Kafka itself.
For the purposes of this blog, I cloned my MongoDB instance from the Ubiquiti controller onto a separate server. For a real-life example then we’d use the live controller itself – since working against a clone means that any new changes to the data (such as new access points being created) won’t be available to us.
You can use a tool such as Robo 3T to explore the data that Ubiqiuti has within it:
Setting up Debezium to stream the data from MongoDB is straightforward – you can follow the steps in this guide. After doing it, you’ll have a bunch of Kafka topics, each reflecting the data in each of the MongoDB collections. The two that we’re interested in for this article are:
- device – metadata for access points
- user – metadata for user devices (i.e. stuff that connects to the access points—phones, computers, etc)
Let’s take a look at the data we’ve brought in, using KSQL. Create a stream over the inbound Device data topic (which is metadata about the access points), and use the EXTRACTJSONFIELD function to show specific fields:
ksql> CREATE STREAM DEVICE_RAW (after VARCHAR) WITH (KAFKA_TOPIC='ubnt.ace.device',VALUE_FORMAT='AVRO');
ksql> SELECT EXTRACTJSONFIELD(after,'$.name'),EXTRACTJSONFIELD(after,'$.ip') FROM DEVICE_RAW;
Unifi AP - Study | 192.168.10.68
Unifi AP - Attic | 192.168.10.67
ubnt.moffatt.me | 77.102.5.159
Unifi AP - Pantry | 192.168.10.71
Now let’s declare all the columns of interest in our schema, and using CREATE STREAM AS SELECT (“CSAS”) generate an Avro topic based on the source stream. This resulting topic will hold not only the transformed data that’s currently on the source topic from MongoDB, but also any subsequent changes to that data.
ksql> CREATE STREAM UBNT_DEVICE_SRC AS \
SELECT EXTRACTJSONFIELD(after,'$._id') as id, \
EXTRACTJSONFIELD(after,'$.name') as name, \
EXTRACTJSONFIELD(after,'$.ip') as ip, \
EXTRACTJSONFIELD(after,'$.mac') as mac, \
EXTRACTJSONFIELD(after,'$.model') as model, \
EXTRACTJSONFIELD(after,'$.version') as version \
FROM DEVICE_RAW;
ksql> SELECT id, name, ip, mac, model, version FROM UBNT_DEVICE_SRC;
{"$oid":"58385328e4b001431e4e497a"} | Unifi AP - Study | 192.168.10.68 | xx:xx:xx:xx:xx:xx | BZ2 | 3.7.40.6115
{"$oid":"583854cde4b001431e4e4982"} | Unifi AP - Attic | 192.168.10.67 | xx:xx:xx:xx:xx:xx | BZ2 | 3.7.40.6115
{"$oid":"58b3fb48e4b0b79e50242621"} | ubnt.moffatt.me | 77.102.5.159 | xx:xx:xx:xx:xx:xx | UGW3 | 4.3.34.4943823
{"$oid":"58b406f1e4b0e334d74c46e4"} | Unifi AP - Pantry | 192.168.10.71 | xx:xx:xx:xx:xx:xx | U7PG2 | 3.7.40.6115
Because we want to join this data (which is, in effect, reference data) we need to ensure that the topic’s messages are keyed on the column on which we want to join, which is the IP address.
Let’s see what the key currently is, courtesy of the system column ROWKEY:
ksql> SELECT ROWKEY FROM UBNT_DEVICE_SRC;
{"id":"{ \"$oid\" : \"58b3fb48e4b0b79e50242621\"}"}
{"id":"{ \"$oid\" : \"58385328e4b001431e4e497a\"}"}
{"id":"{ \"$oid\" : \"58b406f1e4b0e334d74c46e4\"}"}
The source topic is keyed on the id field, which traces back to the source MongoDB collection. We want to rekey the topic to use ip instead. KSQL is a simple way to do this, using the PARTITION BY clause:
ksql> CREATE STREAM UBNT_DEVICE_SRC_REKEY AS SELECT * FROM UBNT_DEVICE_SRC PARTITION BY IP;
Message
----------------------------
Stream created and running
----------------------------
Let’s verify that the message key is now the same as the ip field in the message value:
ksql> SELECT ROWKEY, ip FROM UBNT_DEVICE_SRC_REKEY;
192.168.10.68 | 192.168.10.68
77.102.5.159 | 77.102.5.159
192.168.10.67 | 192.168.10.67
Perfect! The final part of this is to take the resulting Kafka topic from this KSQL streaming transformation and use it as the basis for our KSQL table which will be joined to the syslog data.
ksql> CREATE TABLE UBNT_DEVICE WITH (KAFKA_TOPIC='UBNT_DEVICE_SRC_REKEY',VALUE_FORMAT='AVRO',KEY='IP');
It’s crucial that our table’s topic messages are keyed on the join column which we will be using, so let’s verify again that it is indeed the case in our new table:
ksql> SELECT ROWKEY, IP, NAME FROM UBNT_DEVICE;
192.168.10.68 | 192.168.10.68 | Unifi AP - Study
192.168.10.71 | 192.168.10.71 | Unifi AP - Pantry
192.168.10.67 | 192.168.10.67 | Unifi AP - Attic
77.102.5.159 | 77.102.5.159 | ubnt.moffatt.me
|
Q: Why did we create a STREAM of device data, and then a TABLE? When should we use STREAM and when should we use TABLE?
A: Great question! Logically, we are using the device data as a TABLE. That is, we want to join an inbound stream of events to our device data in order to enrich it. We want to know for a given key, what the corresponding values are. For a given device row, what’s its name, it’s model, it’s version etc. So it is most definitely a TABLE.
But, in order to join to a TABLE, that TABLE must be keyed on the join column. And as we saw from inspecting ROWKEY above, this was not the case. So we utilised KSQL’s powerful re-keying functionality to rekey the topic automagically. And to do that, we treat the inbound data as a STREAM. Why? Because it’s simply an inbound Kafka topic of events, partitioned on one column and on which we want to partition another. Each event (in this context, a change to the source devicedata on MongoDB) simply needs re-routing to the output topic with the new partitioning key.
|
Joining Ubiquiti syslog events with access point reference data
Having defined our inbound stream of Ubiquiti events (captured through Kafka Connect’s syslog connector), and device reference data sourced from MongoDB (snapshotted and changes both streamed through Kafka Connect from Debezium), we can join the two, which is remarkably straightforward to anyone familiar with SQL. Here we’re showing each syslog message, enriched with the name of the access point from which it originated:
ksql> SELECT D.NAME, L.MESSAGE \
FROM UBNT_SYSLOG L \
LEFT JOIN UBNT_DEVICE D \
ON L.HOSTNAME=D.IP;
Unifi AP - Pantry | ("U7PG2,f09fc2000000,v3.7.40.6115") kernel: [5255656.050000] ieee80211_ioctl_set_ratelimit: node with aid 8 and mac cc:2d:b7:xx:xx:xx has been tagged non rate-limiting
Unifi AP - Attic | ("BZ2,dc9fdbxxxxxx,v3.7.40.6115") hostapd: ath1: STA 3c:2e:f9:xx:xx:xx IEEE 802.11: associated
Unifi AP - Attic | ("BZ2,dc9fdbxxxxxx,v3.7.40.6115") syslog: dpi.dpi_stainfo_notify(): dpi not enable
In the syslog data from Ubiquiti is a whole wealth of events, many of them more low-level than we may be interested in. One of the things that is useful to track is user devices connecting to access points, and we can easily expose this here using a SQL predicate. We can also expose the timestamp at which this happened, made human-readable with the TIMESTAMPTOSTRING function:
ksql> SELECT TIMESTAMPTOSTRING(L.ROWTIME, 'yyyy-MM-dd HH:mm:ss') AS CONNECT_TS, D.NAME, L.MESSAGE \
FROM UBNT_SYSLOG L \
LEFT JOIN UBNT_DEVICE D \
ON L.HOSTNAME=D.IP \
WHERE L.MESSAGE LIKE '% associated%';
2018-03-28 09:37:33 | Unifi AP - Attic | ("BZ2,dc9fdbxxxxxx,v3.7.40.6115") hostapd: ath1: STA 3c:2e:f9:xx:xx:xx IEEE 802.11: associated
2018-03-27 17:15:11 | Unifi AP - Study | ("BZ2,24a43cde91a0,v3.7.40.6115") hostapd: ath1: STA fc:a1:83:xx:xx:xx IEEE 802.11: associated
So this is pretty cool, as we can now see as events occur more information about them—in this case the access point that a device is joining. Let’s persist it as a stream, and add in the derivation of the MAC address of the connecting device, extracted using the SUBSTRING function:
ksql> CREATE STREAM UBNT_SYSLOG_AP_CONNECTS AS \
SELECT D.NAME AS AP_NAME, \
SUBSTRING(L.MESSAGE,53,70) as USER_MAC \
FROM UBNT_SYSLOG L \
LEFT JOIN UBNT_DEVICE D \
ON L.HOSTNAME=D.IP \
WHERE L.MESSAGE LIKE '% associated%';
Message
----------------------------
Stream created and running
----------------------------
ksql> SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss') , AP_NAME, USER_MAC </span>
FROM UBNT_SYSLOG_AP_CONNECTS;
2018-03-28 09:37:33 | Unifi AP - Attic | 3c:2e:f9:xx:xx:xx
2018-03-27 17:15:11 | Unifi AP - Study | fc:a1:83:xx:xx:xx
But what about the user device—the third column in the above output? All we have is a MAC address (obfuscated in the examples above). Wouldn’t it be nice to see the name of the device as well as the access point? Well, you know what’s coming now!
Joining Ubiquiti syslog events with access point and device reference data
In the same way as we saw above how to manipulate the inbound stream of snapshotted device (access point) data and subsequent changes (streamed from MongoDB via Debezium), we’ll do the same here for the device information, which is found in the user collection. The steps are:
- Declare a raw STREAM on source user MongoDB collection data, in which all data resides in the after field
ksql> CREATE STREAM USER_RAW (AFTER VARCHAR) WITH (KAFKA_TOPIC='ubnt.ace.user',VALUE_FORMAT='AVRO');
Message
----------------
Stream created
----------------
- Declare a derived STREAM in which columns are extracted from the source after field
ksql> CREATE STREAM UBNT_USER_SRC AS SELECT EXTRACTJSONFIELD(after,'$.mac') as mac, \
EXTRACTJSONFIELD(after,'$.oui') as oui, \
EXTRACTJSONFIELD(after,'$.name') as name, \
EXTRACTJSONFIELD(after,'$.hostname') as hostname, \
EXTRACTJSONFIELD(after,'$.is_guest') as is_guest \
FROM USER_RAW;
Message
----------------------------
Stream created and running
----------------------------
- Re-key the STREAM by join column (MAC address)
ksql> CREATE STREAM UBNT_USER_SRC_REKEY AS SELECT * FROM UBNT_USER_SRC PARTITION BY MAC;
Message
----------------------------
Stream created and running
----------------------------
- Declare a TABLE on top of the Kafka topic resulting from the re-key operation
ksql> CREATE TABLE UBNT_USER WITH (KAFKA_TOPIC='UBNT_USER_SRC_REKEY',VALUE_FORMAT='AVRO',KEY='MAC');
Message
---------------
Table created
---------------
- Check that the message key (ROWKEY) matches the intended join column (MAC):
ksql> SELECT ROWKEY, MAC, NAME FROM UBNT_USER;
b8:27:eb:xx:xx:xx | b8:27:eb:xx:xx:xx | rpi-01.moffatt.me
ac:bc:32:xx:xx:xx | ac:bc:32:xx:xx:xx | asgard
1e:7e:60:xx:xx:xx | 1e:7e:60:xx:xx:xx | media02.moffatt.me
fc:a1:83:xx:xx:xx | fc:a1:83:xx:xx:xx | Fire 01 (Red)
60:01:94:xx:xx:xx | 60:01:94:xx:xx:xx | Attic lights plug
00:04:20:xx:xx:xx | 00:04:20:xx:xx:xx | Squeezebox - Kitchen
b8:ac:6f:xx:xx:xx | b8:ac:6f:xx:xx:xx | crashplan.moffatt.me
Now we can join between Ubiquiti syslog events and reference information for both access points (persisted above in the UBNT_SYSLOG_AP_CONNECTS stream), and user devices (UBNT_USER):
ksql> SELECT TIMESTAMPTOSTRING(L.ROWTIME, 'yyyy-MM-dd HH:mm:ss') AS CONNECT_TS, \
L.AP_NAME, U.NAME AS USER_DEVICE_NAME , U.HOSTNAME as HOSTNAME, U.IS_GUEST \
FROM UBNT_SYSLOG_AP_CONNECTS L \
LEFT JOIN UBNT_USER U \
ON L.USER_MAC = U.MAC ;
2018-06-11 15:05:06 | Unifi AP - Study | null | ItStillnsWhenIP | false
2018-06-11 15:05:06 | Unifi AP - Study | null | ItStillnsWhenIP | false
2018-06-11 15:13:46 | Unifi AP - Study | Fire 02 (Yellow) | amazon-ca6091cfe | false
So every time a user’s device connects to an access point, we get to see the name of the access point, the name of the user device, and the type of the device. We’ll persist this as a stream, because we’ve not quite finished this exploration yet!
ksql> CREATE STREAM UBNT_AP_USER_DEVICE_CONNECTS AS \
SELECT TIMESTAMPTOSTRING(L.ROWTIME, 'yyyy-MM-dd HH:mm:ss') AS CONNECT_TS, \
L.AP_NAME, U.NAME AS USER_DEVICE_NAME , U.HOSTNAME as HOSTNAME, U.IS_GUEST \
FROM UBNT_SYSLOG_AP_CONNECTS L \
LEFT JOIN UBNT_USER U \
ON L.USER_MAC = U.MAC ;
Taking this enriched stream of data we can use a tool such as Elasticsearch with Kibana on top to provide an easy visualisation of the real-time data, as well as aggregate analysis based upon it:
Enriched streams of data are valuable for analysis that we want to consume and look at, but even more valuable is event-driven alerting on conditions that we’re interested in. We saw in the previous article how we can use something like a simple Python script to drive push-based notifications in response to events on a Kafka topic. Using this pattern we can use a further KSQL expression to send notifications to a topic when a connection is made to an access point from a certain type of device. For example, if I wanted to track whenever my wifi-enabled plugs (yes, really!) reconnect to an access point, I can filter on the device type of “Espressi”:
ksql> SELECT CONNECT_TS, AP_NAME, USER_DEVICE_NAME \
FROM UBNT_AP_USER_DEVICE_CONNECTS \
WHERE DEVICE_TYPE='Espressi';
2018-03-04 14:07:43 | Unifi AP - Study | Wifi Plug - Sitting Room
2018-03-04 14:07:48 | Unifi AP - Study | Attic lights plug
2018-03-04 14:07:42 | Unifi AP - Study | Wifi Plug - Sitting Room
2018-03-04 14:07:42 | Unifi AP - Study | Study light
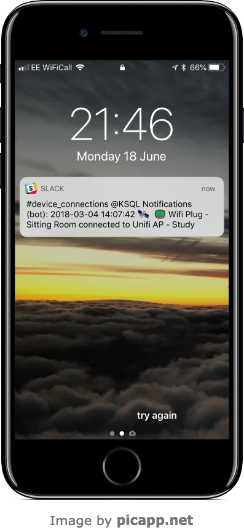
Persisting this to a target stream that the python application is listening to results in a nice push notification every time the device reconnects…
CREATE STREAM KSQL_NOTIFY_DEVICE WITH (VALUE_FORMAT='JSON') AS \
SELECT CONNECT_TS + ' 🛰 📟 ' + USER_DEVICE_NAME + ' connected to ' + AP_NAME AS TEXT, \
'device_connections' AS CHANNEL \
FROM UBNT_AP_USER_DEVICE_CONNECTS5 \
WHERE DEVICE_TYPE='Espressi';
Recap
We’ve come a long way! Let’s remind ourselves what we’ve built:
- Streaming syslog events from multiple devices into Kafka
- Streaming contents and subsequent changes from MongoDB into Kafka
- Filtering syslog events to just include those from Ubiquiti devices
- Enriching Ubiquiti syslog events with both (i) access point name and (ii) user device name and device type
- Streaming enriched Ubiquiti syslog data to Elasticsearch for analysis in Kibana
- Filtering Ubiquiti syslog data to include only wifi connections from devices which are wifi-plugs
- Triggering push notification from Kafka topic to Slack
Summary
In this mini-series of blog articles we’ve seen the power of Apache Kafka—including Kafka Connect—and KSQL to build applications and analytics on Apache Kafka as a streaming platform. Using KSQL, it’s simple to create scalable real-time stream processing applications, using just SQL—no other coding required! Kafka Connect provides a configuration-file based method for powerful streaming integration between sources of data into Kafka, and from Kafka out to targets such as Elasticsearch.
If you’re interested in learning more, you can: