Introducing Connector Private Networking: Join The Upcoming Webinar!
Streaming Data from the Universe with Apache Kafka
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
You might think that data collection in astronomy consists of a lone astronomer pointing a telescope at a single object in a static sky. While that may be true in some cases (I collected the data for my Ph.D. thesis this way), the field of astronomy is rapidly changing into a data-intensive science with real-time needs. Each night, large-scale astronomical telescope surveys detect millions of changing objects in the sky and need to stream results to scientists for time-sensitive, complementary follow-up observations. This data pipeline is a great example of a use case for Apache Kafka®.
Astronomy in real time
Observational astronomers study many different types of objects, from asteroids in our own solar system to galaxies that are billions of lightyears away. Though the timescales on which single astronomical objects change are generally on the order of millions of years, a telescope can detect millions of objects that appear to be changing on a single night. These objects, commonly known as transients, encompass a number of different phenomena including variable stars, gamma-ray bursts, supernova, and moving objects in the solar system like asteroids.
To detect and study these transient objects, many astronomers will collaborate on “sky survey” telescopes, which collect data by taking images as they sweep across the night sky instead of pointing at individual pre-selected targets. The Sloan Digital Sky Survey (SDSS) is an early pioneer of the survey technique, collecting tens of TBs of image data from nearly 1 billion objects. By taking the latest survey images of a swath of the sky and subtracting a previous reference image taken at the same location, astronomers can detect objects that change in brightness or have changed in position.
To fully characterize transient objects, astronomers need to gather data from other telescopes at different wavelengths at nearly the same time. Some phenomena, like supernova “shock breakouts,” may only last on the order of minutes. Astronomers need to be able to collect, process, characterize, and distribute data on these objects in near real time, especially for time-sensitive events.
Recently, a new sky survey came online with the specific aim of quickly detecting transient objects. The Zwicky Transient Facility (ZTF) images the entire Northern Sky every three nights. Using image differencing, ZTF detects about 1,000 objects in each image taken every 45 seconds, amounting to roughly 1 million changing objects per night. The data processing pipeline characterizes these objects, deriving key parameters such as brightness, color, ellipticity, and coordinate location, and broadcasts this information in alert packets.
The case for Apache Kafka
Until recently, the detection rate of transient objects was relatively low and put few requirements on the underlying technology of alert distribution mechanisms. For example, the Astronomer’s Telegrams (ATel), a web service allowing astronomers to manually post and broadcast alerts from transient object detections, has distributed on the order of tens of thousands of alerts since its inception in 1997. In order to distribute the alert data from ZTF’s roughly million of nightly detections, a fully automated and scalable streaming alert distribution is required.
Additionally, ZTF is a precursor survey for an even more technically challenging, upcoming astronomy project called the Large Synoptic Survey Telescope (LSST). The LSST is expected to detect about 10 million transient objects each night, an order of magnitude more than ZTF, with a nightly data stream size of 1–2 TB of messages. The technology underlying the ZTF system should be a prototype that reliably scales to LSST needs.
There were a number of factors we considered in designing an alert distribution for ZTF. First, we needed a system that would reliably distribute each alert message and could allow downstream listeners of the alert stream to rewind or catch up in real time, without losing data in the case of a dropped connection or a slow consumer. The existing standard alert distribution system, called the Virtual Observatory Event Transport Protocol, acts more as a broadcast system, transmitting alerts only if a user is connected. Kafka’s consumer offset management and the ability for consumers to rewind to the beginning of a topic are big draws.
Because these alerts are scientific quality data, an alert serialization format that preserves the integrity of the data so that it can be correctly interpreted by an end user scientist is imperative. For example, correctly storing numerical data as a double versus a float is a requirement for scientific calculations. The predominant existing astronomical alert format uses the semi-structured format XML. For alert stream rates low enough such that scientists can visually inspect messages, this format can definitely be appropriate. For alert rates of millions per night, scientists need a more structured data format for automated analysis pipelines. After researching formats—and reading about Confluent’s suggestion of using Avro with Kafka—we settled on using Avro, an open source, JSON-based binary format, for serializing the data in the alert messages. Avro has the benefits of:
- Being very compact (as opposed to XML’s verbosity)
- Being easy to characterize with simple JSON schemas
- Supporting some degree of schema evolution
- Having a couple of Python libraries for reading and writing data
Another requirement for the alert distribution system is ease of use for the end user. The end user in our case is most likely an astronomy researcher. Much of the code used by modern astronomers is written in Python, so the ZTF alert distribution system endpoints need to at least support Python. We built our alert distribution code in Python, based around Confluent’s Python client for Apache Kafka.
Alert data pipeline and system design
The ZTF telescope sits at the Palomar Observatory in California and takes images of the sky as it sweeps across at a rate of about one image every 45 seconds. The data then go through processing at CalTech’s Infrared Processing and Analysis Center (IPAC). The images are cleaned to remove instrumental and atmospheric effects, as well as differenced to produce transient candidates. The data from these detections are then serialized into Avro binary format.
The Avro alert data schemas for ZTF are defined in JSON documents and are published to GitHub for scientists to use when deserializing data upon receipt. Part of the alert data that we need to distribute is a small cutout image (or “postage stamp”) of the transient candidate. With Avro, we can have data fields serialize as type bytes, which allows for the inclusion of binary format data, such as these image cutouts or generally any individual file: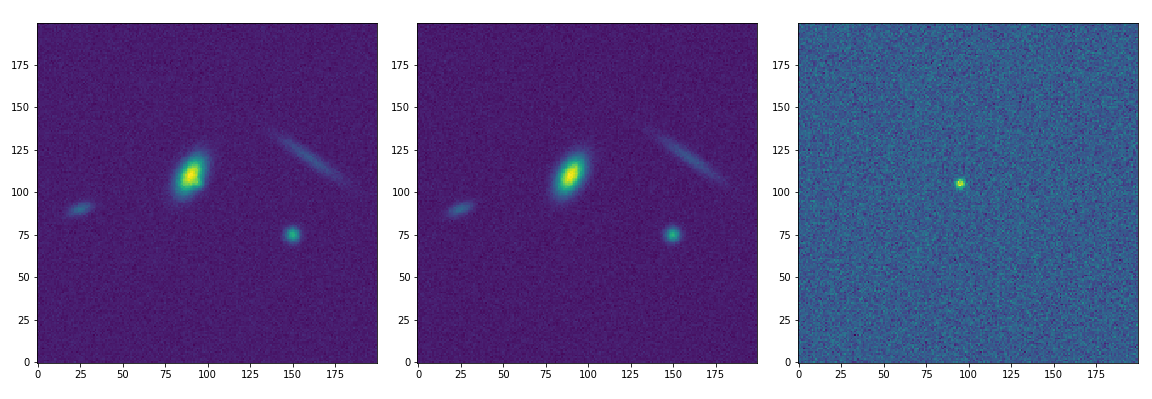
Image cutouts from simulated data of a supernova detection. Left: Science image. Center: Template sky image. Right: Difference image constructed by subtracting the template from the science image.
Serialized alerts are produced to a Kafka broker, with each night’s data written to its own topic. Data older than two weeks is expired from Kafka. The IPAC’s Kafka broker is available to only two external consumer for security purposes—a downstream Kafka system at the University of Washington (UW) and another Kafka system in a commercial cloud, both using MirrorMaker to mirror available alert stream topics.
The University of Washington runs a cluster of three Kafka brokers, each deployed in a separate Docker container (built on top of Confluent’s Docker Hub images), that feeds a permanent data archive of Avro files and allows connections from a number of external collaborations of scientists focused on different subfields of astronomy. Topics are separated into 16 partitions so that consumers of the stream can parallelize readers into a group of up to 16 for faster reading and parallel downstream filtering and processing.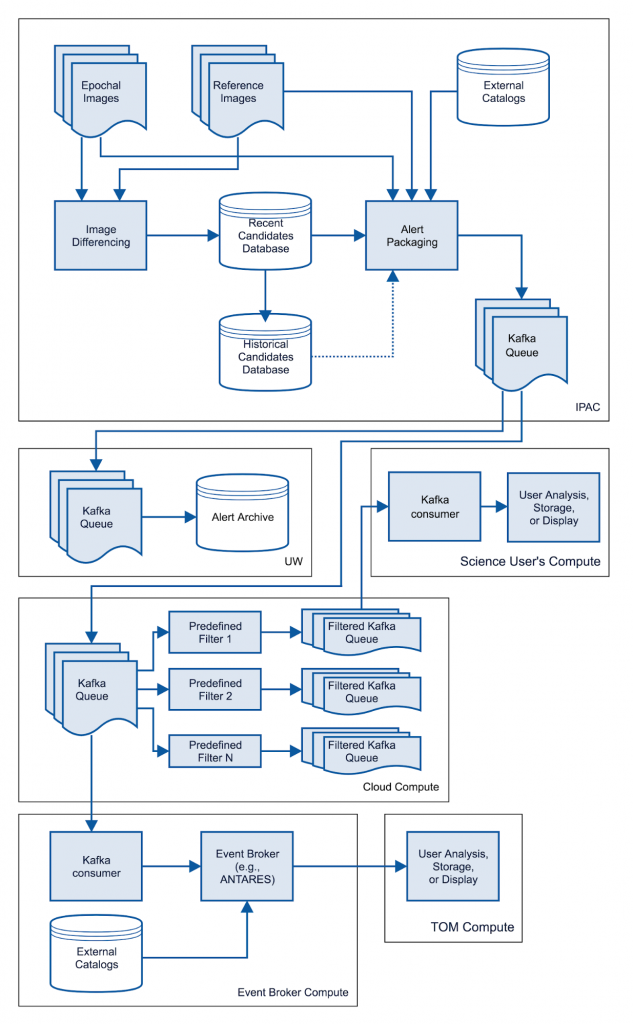
Diagram of the flow of alert data through the ZTF Alert Distribution System: Transient candidate alerts are submitted to a Kafka cluster at IPAC and mirrored at UW and a commercial cloud. Downstream filtering algorithms classify and separate different types of objects. End user scientists can subscribe to topics for objects of interest, and collaborations of scientists (known in the astronomical community as event brokers) can also subscribe and redistribute alerts enriched with additional external data.
The cloud-based Kafka system is public facing for other astronomy researchers. Scientists can write scientific filters to automatically apply algorithms such as classifiers to detect and tag different types of objects (e.g., supernova, variable stars, near-Earth objects). The filters can be written simply in Python and can be deployed separately in different Docker containers. Here is an example of the code a scientist would write:
class Filter001(AlertFilter):
def filter(self, alert):
if ((alert['source']['signal_level'] > 5) &
(alert['source']['brightness'] > 0.00003631)):
return True
else:
return False
For objects that pass a filter, the filter returns True, and the alert data message is then produced to a new topic just for that type of object that other scientists can then subscribe to.
Streaming millions of detections
The ZTF pipeline produces anywhere from 600,000 to 1.2 million alerts per night. We have stress tested the system up to 2 million alerts without any technical issues. Each alert packet is about 60 KB in size, dominated mostly by the cutout images, for a total volume of up to 70 GB of data pushed through the system each night. Serialized alert data is available to end users around 20 minutes after an image is taken on the telescope, with the majority of that time taken up by the image differencing pipeline. From the main Kafka distribution hub to external consumers, the transfer time is about four seconds.
Kafka has been a great tool for powering the tech behind attacking astronomical data distribution and data analysis pipeline challenges, meeting scalability demands, and enabling science in near real time. It is relatively easy to use and simple enough for a scientist to start prototyping with. I’ll be continuing to explore ways to work with it to enable real-time data science pipelines for projects here at High Alpha Studio.
Interested in more?
If you’d like to know more, you can download the Confluent Platform to get started with the leading distribution of Apache Kafka.
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.